 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Network Approaches for Leather Defect Classification
Jun 15, 2019

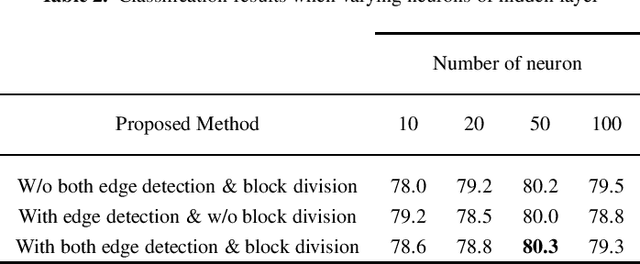
Genuine leather, such as the hides of cows, crocodiles, lizards and goats usually contain natural and artificial defects, like holes, fly bites, tick marks, veining, cuts, wrinkles and others. A traditional solution to identify the defects is by manual defect inspection, which involves skilled experts. It is time consuming and may incur a high error rate and results in low productivity. This paper presents a series of automatic image processing processes to perform the classification of leather defects by adopting deep learning approaches. Particularly, the leather images are first partitioned into small patches,then it undergoes a pre-processing technique, namely the Canny edge detection to enhance defect visualization. Next, artificial neural network (ANN) and convolutional neural network (CNN) are employed to extract the rich image features. The best classification result achieved is 80.3 %, evaluated on a data set that consists of 2000 samples. In addition, the performance metrics such as confusion matrix and Receiver Operating Characteristic (ROC) are reported to demonstrate the efficiency of the method proposed.
Integrated Neural Network and Machine Vision Approach For Leather Defect Classification
May 28, 2019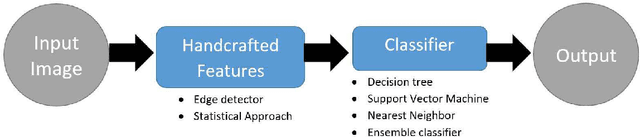
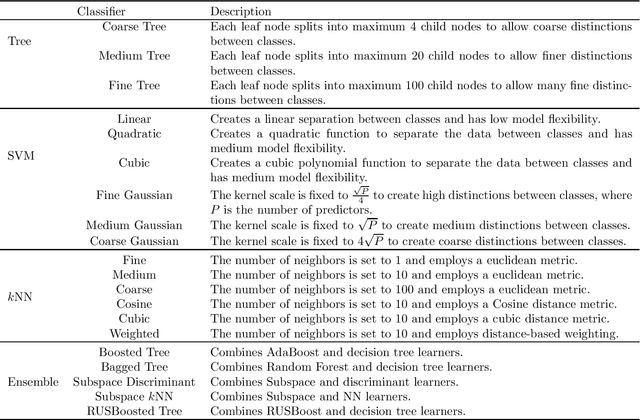

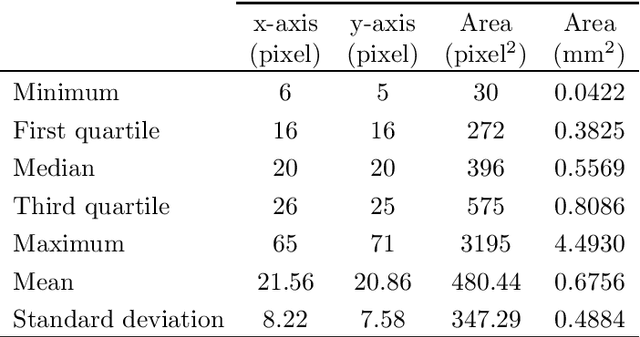
Leather is a type of natural, durable, flexible, soft, supple and pliable material with smooth texture. It is commonly used as a raw material to manufacture luxury consumer goods for high-end customers. To ensure good quality control on the leather products, one of the critical processes is the visual inspection step to spot the random defects on the leather surfaces and it is usually conducted by experienced experts. This paper presents an automatic mechanism to perform the leather defect classification. In particular, we focus on detecting tick-bite defects on a specific type of calf leather. Both the handcrafted feature extractors (i.e., edge detectors and statistical approach) and data-driven (i.e., artificial neural network) methods are utilized to represent the leather patches. Then, multiple classifiers (i.e., decision trees, Support Vector Machines, nearest neighbour and ensemble classifiers) are exploited to determine whether the test sample patches contain defective segments. Using the proposed method, we managed to get a classification accuracy rate of 84% from a sample of approximately 2500 pieces of 400 * 400 leather patches.
Evaluation of the Spatio-Temporal features and GAN for Micro-expression Recognition System
Apr 03, 2019
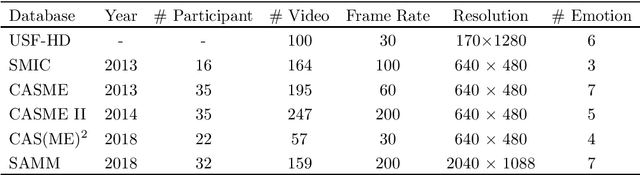
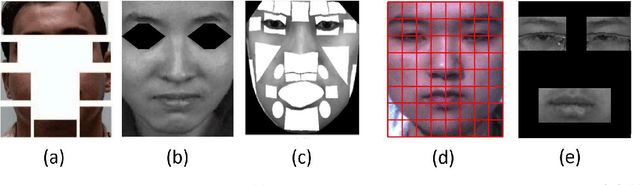
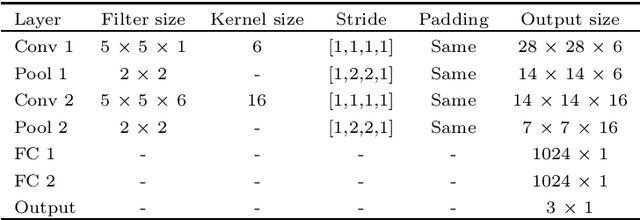
Owing to the development and advancement of artificial intelligence, numerous works were established in the human facial expression recognition system. Meanwhile, the detection and classification of micro-expressions are attracting attentions from various research communities in the recent few years. In this paper, we first review the processes of a conventional optical-flow-based recognition system, which comprised of facial landmarks annotations, optical flow guided images computation, features extraction and emotion class categorization. Secondly, a few approaches have been proposed to improve the feature extraction part, such as exploiting GAN to generate more image samples. Particularly, several variations of optical flow are computed in order to generate optimal images to lead to high recognition accuracy. Next, GAN, a combination of Generator and Discriminator, is utilized to generate new "fake" images to increase the sample size. Thirdly, a modified state-of-the-art Convolutional neural networks is proposed. To verify the effectiveness of the the proposed method, the results are evaluated on spontaneous micro-expression databases, namely SMIC, CASME II and SAMM. Both the F1-score and accuracy performance metrics are reported in this paper.
Automatic Defect Segmentation on Leather with Deep Learning
Mar 28, 2019
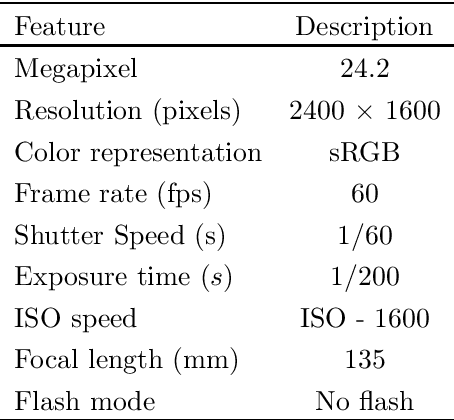
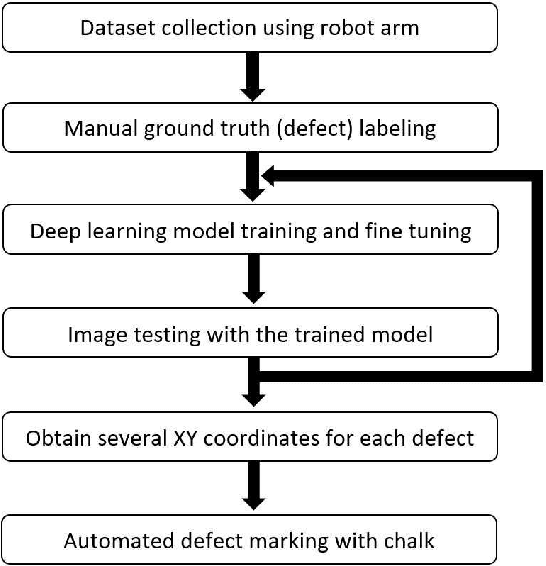

Leather is a natural and durable material created through a process of tanning of hides and skins of animals. The price of the leather is subjective as it is highly sensitive to its quality and surface defects condition. In the literature, there are very few works investigating on the defects detection for leather using automatic image processing techniques. The manual defect inspection process is essential in an leather production industry to control the quality of the finished products. However, it is tedious, as it is labour intensive, time consuming, causes eye fatigue and often prone to human error. In this paper, a fully automatic defect detection and marking system on a calf leather is proposed. The proposed system consists of a piece of leather, LED light, high resolution camera and a robot arm. Succinctly, a machine vision method is presented to identify the position of the defects on the leather using a deep learning architecture. Then, a series of processes are conducted to predict the defect instances, including elicitation of the leather images with a robot arm, train and test the images using a deep learning architecture and determination of the boundary of the defects using mathematical derivation of the geometry. Note that, all the processes do not involve human intervention, except for the defect ground truths construction stage. The proposed algorithm is capable to exhibit 91.5% segmentation accuracy on the train data and 70.35% on the test data. We also report confusion matrix, F1-score, precision and specificity, sensitivity performance metrics to further verify the effectiveness of the proposed approach.
A Shallow Triple Stream Three-dimensional CNN for Micro-expression Recognition System
Feb 10, 2019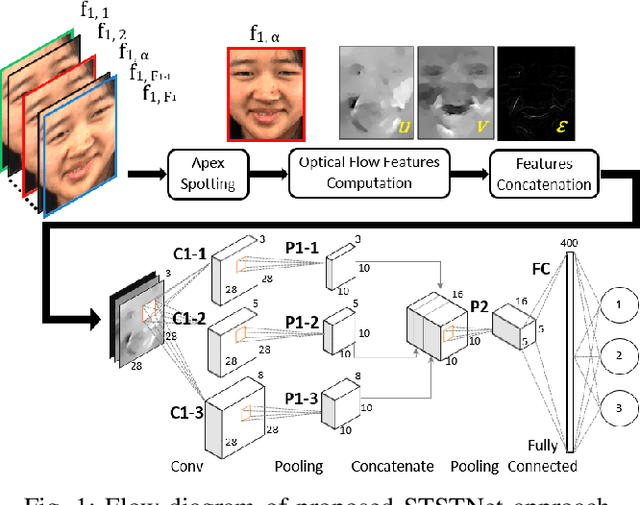
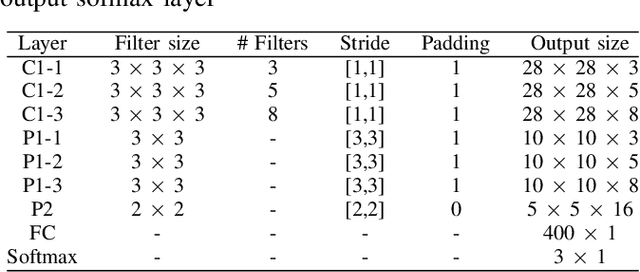
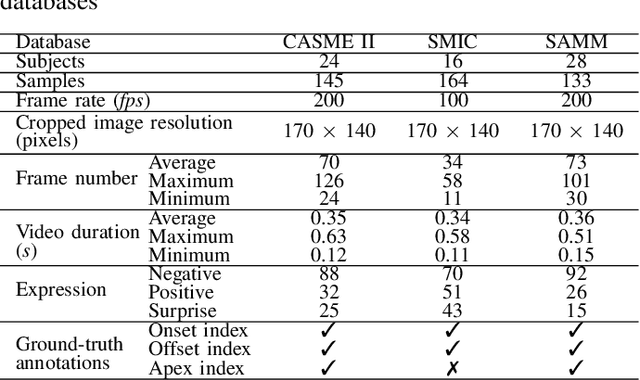
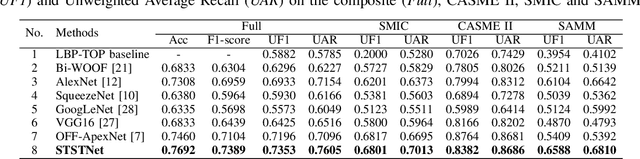
In the recent year, the state-of-the-arts of facial micro-expression recognition task have been significantly advanced by the emergence of data-driven approaches based on deep learning. Due to the superb learning capacity of deep learning, it generates promising performance beyond the traditional handcrafted approaches. Recently, many researchers have focused on developing better networks by increasing its depth, as deep networks can effectively approximate certain function classes more efficiently than shallow ones. In this paper, we aim to design a shallow network to extract the high level features of the micro-expression details. Specifically, a two-layer neural network, namely Shallow Triple Stream Three-dimensional CNN (STSTNet) is proposed. The network is capable to learn the features from three optical flow features (i.e., optical strain, horizontal and vertical optical flow images) computed from the onset and apex frames from each video. Our experimental results demonstrate the viability of the proposed STSTNet, which exhibits the UAR recognition results of 76.05%, 70.13%, 86.86% and 68.10% in composite, SMIC, CASME II and SAMM databases, respectively.
Automatic Surface Area and Volume Prediction on Ellipsoidal Ham using Deep Learning
Jan 15, 2019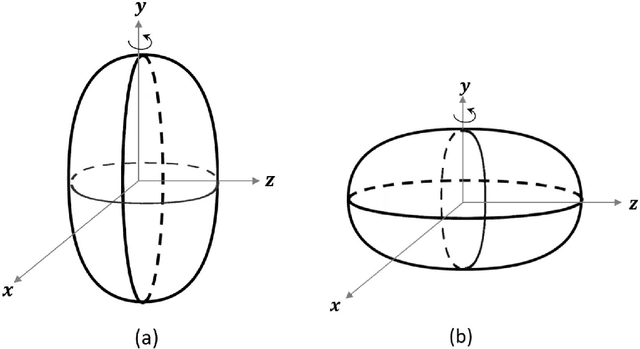
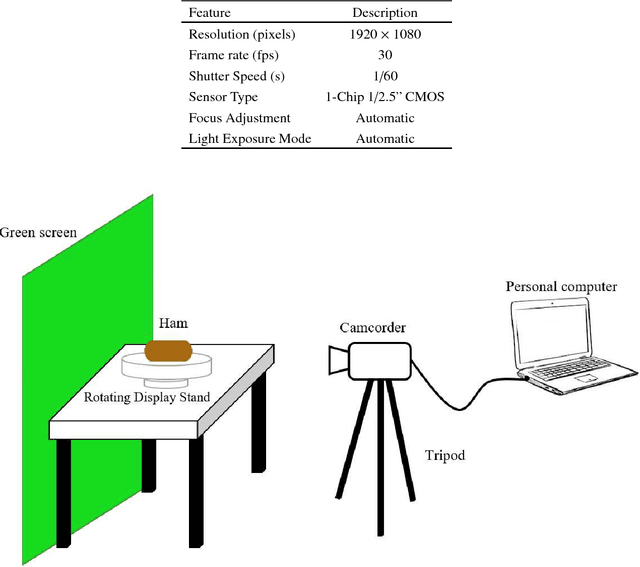

This paper presents novel methods to predict the surface and volume of the ham through a camera. This implies that the conventional weight measurement to obtain in the object's volume can be neglected and hence it is economically effective. Both of the measurements are obtained in the following two ways: manually and automatically. The former is assume as the true or exact measurement and the latter is through a computer vision technique with some geometrical analysis that includes mathematical derived functions. For the automatic implementation, most of the existing approaches extract the features of the food material based on handcrafted features and to the best of our knowledge this is the first attempt to estimate the surface area and volume on ham with deep learning features. We address the estimation task with a Mask Region-based CNN (Mask R-CNN) approach, which well performs the ham detection and semantic segmentation from a video. The experimental results demonstrate that the algorithm proposed is robust as promising surface area and volume estimation are obtained for two angles of the ellipsoidal ham (i.e., horizontal and vertical positions). Specifically, in the vertical ham point of view, it achieves an overall accuracy up to 95% whereas the horizontal ham reaches 80% of accuracy.
OFF-ApexNet on Micro-expression Recognition System
May 10, 2018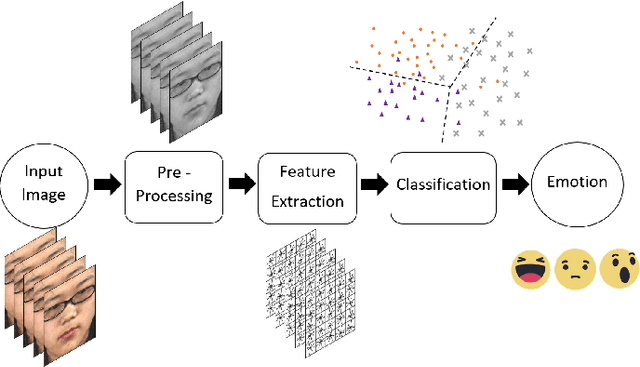
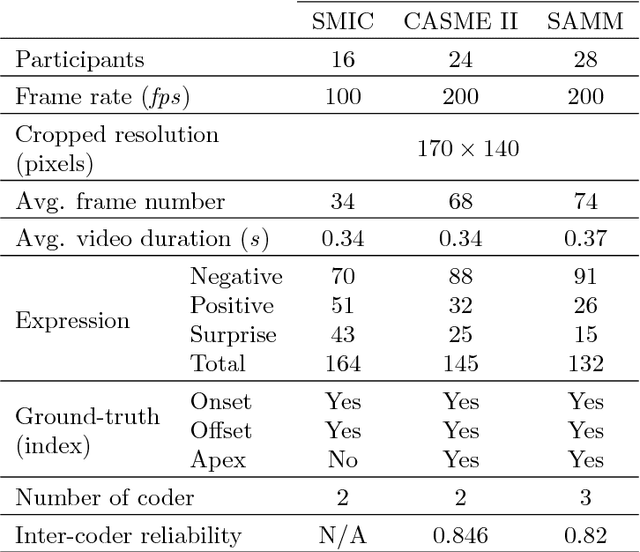
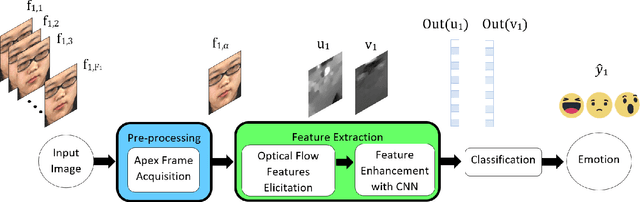
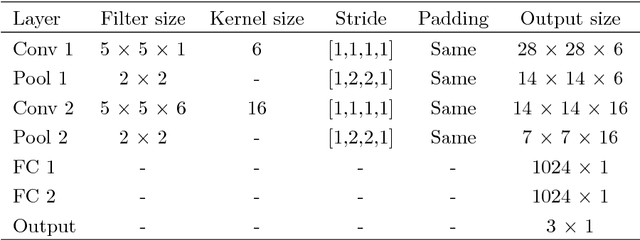
When a person attempts to conceal an emotion, the genuine emotion is manifest as a micro-expression. Exploration of automatic facial micro-expression recognition systems is relatively new in the computer vision domain. This is due to the difficulty in implementing optimal feature extraction methods to cope with the subtlety and brief motion characteristics of the expression. Most of the existing approaches extract the subtle facial movements based on hand-crafted features. In this paper, we address the micro-expression recognition task with a convolutional neural network (CNN) architecture, which well integrates the features extracted from each video. A new feature descriptor, Optical Flow Features from Apex frame Network (OFF-ApexNet) is introduced. This feature descriptor combines the optical ow guided context with the CNN. Firstly, we obtain the location of the apex frame from each video sequence as it portrays the highest intensity of facial motion among all frames. Then, the optical ow information are attained from the apex frame and a reference frame (i.e., onset frame). Finally, the optical flow features are fed into a pre-designed CNN model for further feature enhancement as well as to carry out the expression classification. To evaluate the effectiveness of OFF-ApexNet, comprehensive evaluations are conducted on three public spontaneous micro-expression datasets (i.e., SMIC, CASME II and SAMM). The promising recognition result suggests that the proposed method can optimally describe the significant micro-expression details. In particular, we report that, in a multi-database with leave-one-subject-out cross-validation experimental protocol, the recognition performance reaches 74.60% of recognition accuracy and F-measure of 71.04%. We also note that this is the first work that performs cross-dataset validation on three databases in this domain.