 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGM-TCNet: Gated Multi-scale Temporal Convolutional Network using Emotion Causality for Speech Emotion Recognition
Oct 28, 2022In human-computer interaction, Speech Emotion Recognition (SER) plays an essential role in understanding the user's intent and improving the interactive experience. While similar sentimental speeches own diverse speaker characteristics but share common antecedents and consequences, an essential challenge for SER is how to produce robust and discriminative representations through causality between speech emotions. In this paper, we propose a Gated Multi-scale Temporal Convolutional Network (GM-TCNet) to construct a novel emotional causality representation learning component with a multi-scale receptive field. GM-TCNet deploys a novel emotional causality representation learning component to capture the dynamics of emotion across the time domain, constructed with dilated causal convolution layer and gating mechanism. Besides, it utilizes skip connection fusing high-level features from different gated convolution blocks to capture abundant and subtle emotion changes in human speech. GM-TCNet first uses a single type of feature, mel-frequency cepstral coefficients, as inputs and then passes them through the gated temporal convolutional module to generate the high-level features. Finally, the features are fed to the emotion classifier to accomplish the SER task. The experimental results show that our model maintains the highest performance in most cases compared to state-of-the-art techniques.
* The source code is available at: https://github.com/Jiaxin-Ye/GM-TCNet
CTL-MTNet: A Novel CapsNet and Transfer Learning-Based Mixed Task Net for the Single-Corpus and Cross-Corpus Speech Emotion Recognition
Jul 18, 2022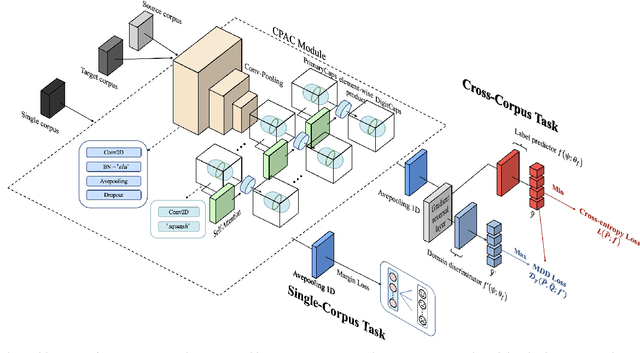
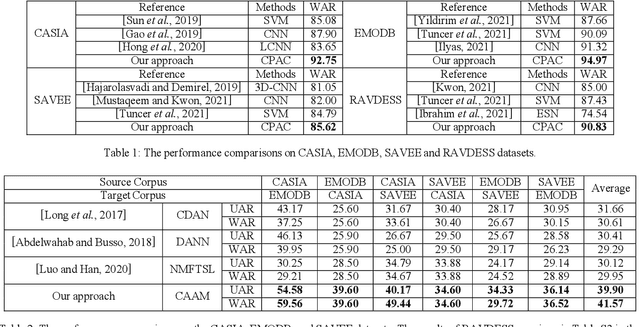
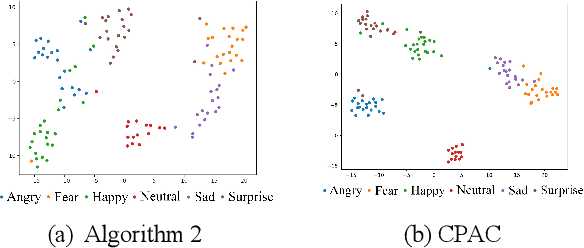

Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. An essential challenge in SER is to extract common attributes from different speakers or languages, especially when a specific source corpus has to be trained to recognize the unknown data coming from another speech corpus. To address this challenge, a Capsule Network (CapsNet) and Transfer Learning based Mixed Task Net (CTLMTNet) are proposed to deal with both the singlecorpus and cross-corpus SER tasks simultaneously in this paper. For the single-corpus task, the combination of Convolution-Pooling and Attention CapsNet module CPAC) is designed by embedding the self-attention mechanism to the CapsNet, guiding the module to focus on the important features that can be fed into different capsules. The extracted high-level features by CPAC provide sufficient discriminative ability. Furthermore, to handle the cross-corpus task, CTL-MTNet employs a Corpus Adaptation Adversarial Module (CAAM) by combining CPAC with Margin Disparity Discrepancy (MDD), which can learn the domain-invariant emotion representations through extracting the strong emotion commonness. Experiments including ablation studies and visualizations on both singleand cross-corpus tasks using four well-known SER datasets in different languages are conducted for performance evaluation and comparison. The results indicate that in both tasks the CTL-MTNet showed better performance in all cases compared to a number of state-of-the-art methods. The source code and the supplementary materials are available at: https://github.com/MLDMXM2017/CTLMTNet