 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Transformer: Adapting Spherical Signal to CNNs
Jan 24, 2021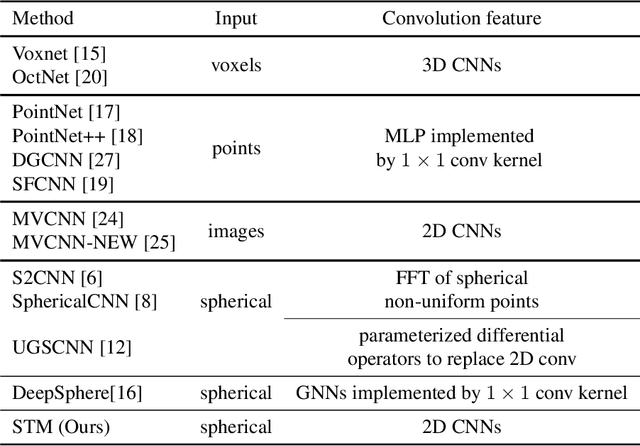
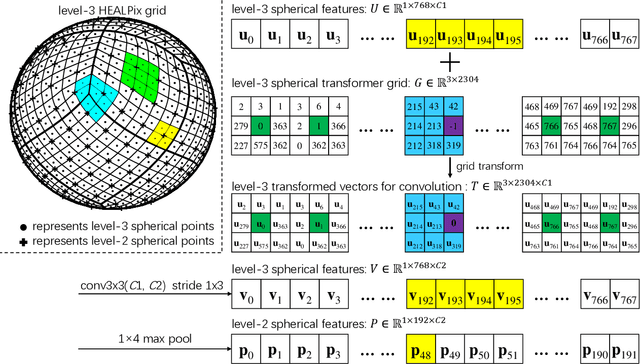
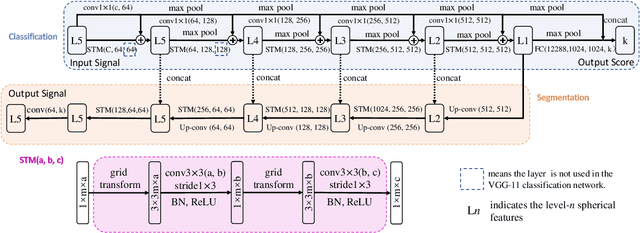
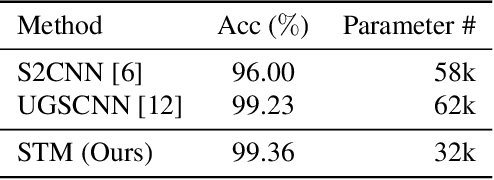
Convolutional neural networks (CNNs) have been widely used in various vision tasks, e.g. image classification, semantic segmentation, etc. Unfortunately, standard 2D CNNs are not well suited for spherical signals such as panorama images or spherical projections, as the sphere is an unstructured grid. In this paper, we present Spherical Transformer which can transform spherical signals into vectors that can be directly processed by standard CNNs such that many well-designed CNNs architectures can be reused across tasks and datasets by pretraining. To this end, the proposed method first uses locally structured sampling methods such as HEALPix to construct a transformer grid by using the information of spherical points and its adjacent points, and then transforms the spherical signals to the vectors through the grid. By building the Spherical Transformer module, we can use multiple CNN architectures directly. We evaluate our approach on the tasks of spherical MNIST recognition, 3D object classification and omnidirectional image semantic segmentation. For 3D object classification, we further propose a rendering-based projection method to improve the performance and a rotational-equivariant model to improve the anti-rotation ability. Experimental results on three tasks show that our approach achieves superior performance over state-of-the-art methods.
InSphereNet: a Concise Representation and Classification Method for 3D Object
Jan 03, 2020
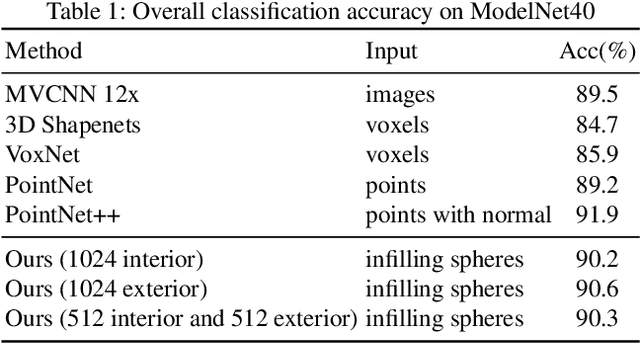
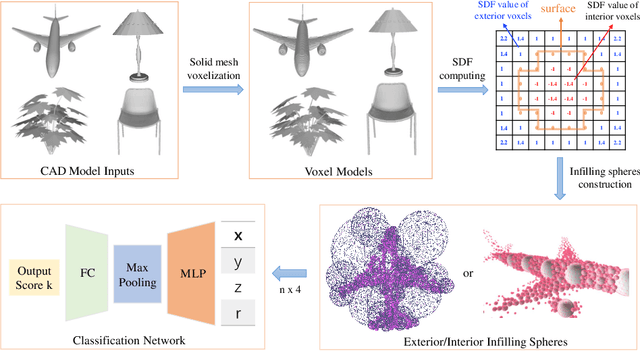
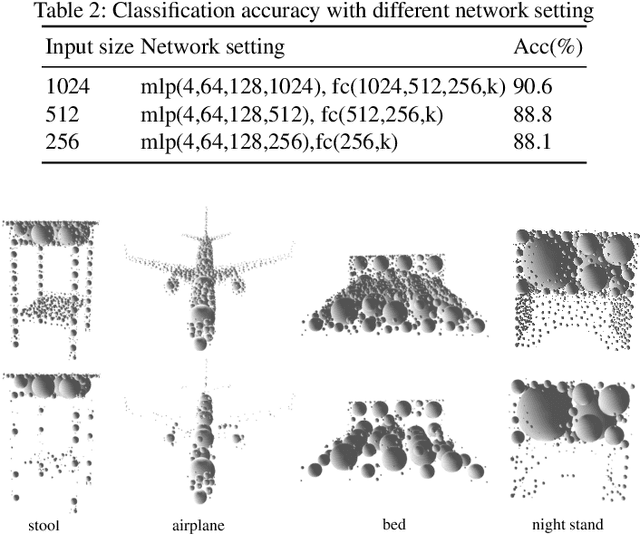
In this paper, we present an InSphereNet method for the problem of 3D object classification. Unlike previous methods that use points, voxels, or multi-view images as inputs of deep neural network (DNN), the proposed method constructs a class of more representative features named infilling spheres from signed distance field (SDF). Because of the admirable spatial representation of infilling spheres, we can not only utilize very fewer number of spheres to accomplish classification task, but also design a lightweight InSphereNet with less layers and parameters than previous methods. Experiments on ModelNet40 show that the proposed method leads to superior performance than PointNet and PointNet++ in accuracy. In particular, if there are only a few dozen sphere inputs or about 100000 DNN parameters, the accuracy of our method remains at a very high level (over 88%). This further validates the conciseness and effectiveness of the proposed InSphere 3D representation. Keywords: 3D object classification , signed distance field , deep learning , infilling sphere