 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Embedding Table Optimization and Multi-Epoch Training in Pinterest Ads Conversion
May 08, 2025Deep learning for conversion prediction has found widespread applications in online advertising. These models have become more complex as they are trained to jointly predict multiple objectives such as click, add-to-cart, checkout and other conversion types. Additionally, the capacity and performance of these models can often be increased with the use of embedding tables that encode high cardinality categorical features such as advertiser, user, campaign, and product identifiers (IDs). These embedding tables can be pre-trained, but also learned end-to-end jointly with the model to directly optimize the model objectives. Training these large tables is challenging due to: gradient sparsity, the high cardinality of the categorical features, the non-uniform distribution of IDs and the very high label sparsity. These issues make training prone to both slow convergence and overfitting after the first epoch. Previous works addressed the multi-epoch overfitting issue by using: stronger feature hashing to reduce cardinality, filtering of low frequency IDs, regularization of the embedding tables, re-initialization of the embedding tables after each epoch, etc. Some of these techniques reduce overfitting at the expense of reduced model performance if used too aggressively. In this paper, we share key learnings from the development of embedding table optimization and multi-epoch training in Pinterest Ads Conversion models. We showcase how our Sparse Optimizer speeds up convergence, and how multi-epoch overfitting varies in severity between different objectives in a multi-task model depending on label sparsity. We propose a new approach to deal with multi-epoch overfitting: the use of a frequency-adaptive learning rate on the embedding tables and compare it to embedding re-initialization. We evaluate both methods offline using an industrial large-scale production dataset.
STRMs: Spatial Temporal Reasoning Models for Vision-Based Localization Rivaling GPS Precision
Mar 11, 2025This paper explores vision-based localization through a biologically-inspired approach that mirrors how humans and animals link views or perspectives when navigating their world. We introduce two sequential generative models, VAE-RNN and VAE-Transformer, which transform first-person perspective (FPP) observations into global map perspective (GMP) representations and precise geographical coordinates. Unlike retrieval-based methods, our approach frames localization as a generative task, learning direct mappings between perspectives without relying on dense satellite image databases. We evaluate these models across two real-world environments: a university campus navigated by a Jackal robot and an urban downtown area navigated by a Tesla sedan. The VAE-Transformer achieves impressive precision, with median deviations of 2.29m (1.37% of environment size) and 4.45m (0.35% of environment size) respectively, outperforming both VAE-RNN and prior cross-view geo-localization approaches. Our comprehensive Localization Performance Characteristics (LPC) analysis demonstrates superior performance with the VAE-Transformer achieving an AUC of 0.777 compared to 0.295 for VIGOR 200 and 0.225 for TransGeo, establishing a new state-of-the-art in vision-based localization. In some scenarios, our vision-based system rivals commercial smartphone GPS accuracy (AUC of 0.797) while requiring 5x less GPU memory and delivering 3x faster inference than existing methods in cross-view geo-localization. These results demonstrate that models inspired by biological spatial navigation can effectively memorize complex, dynamic environments and provide precise localization with minimal computational resources.
Hessian Aware Quantization of Spiking Neural Networks
Apr 29, 2021


To achieve the low latency, high throughput, and energy efficiency benefits of Spiking Neural Networks (SNNs), reducing the memory and compute requirements when running on a neuromorphic hardware is an important step. Neuromorphic architecture allows massively parallel computation with variable and local bit-precisions. However, how different bit-precisions should be allocated to different layers or connections of the network is not trivial. In this work, we demonstrate how a layer-wise Hessian trace analysis can measure the sensitivity of the loss to any perturbation of the layer's weights, and this can be used to guide the allocation of a layer-specific bit-precision when quantizing an SNN. In addition, current gradient based methods of SNN training use a complex neuron model with multiple state variables, which is not ideal for compute and memory efficiency. To address this challenge, we present a simplified neuron model that reduces the number of state variables by 4-fold while still being compatible with gradient based training. We find that the impact on model accuracy when using a layer-wise bit-precision correlated well with that layer's Hessian trace. The accuracy of the optimal quantized network only dropped by 0.2%, yet the network size was reduced by 58%. This reduces memory usage and allows fixed-point arithmetic with simpler digital circuits to be used, increasing the overall throughput and energy efficiency.
A general learning system based on neuron bursting and tonic firing
Oct 22, 2018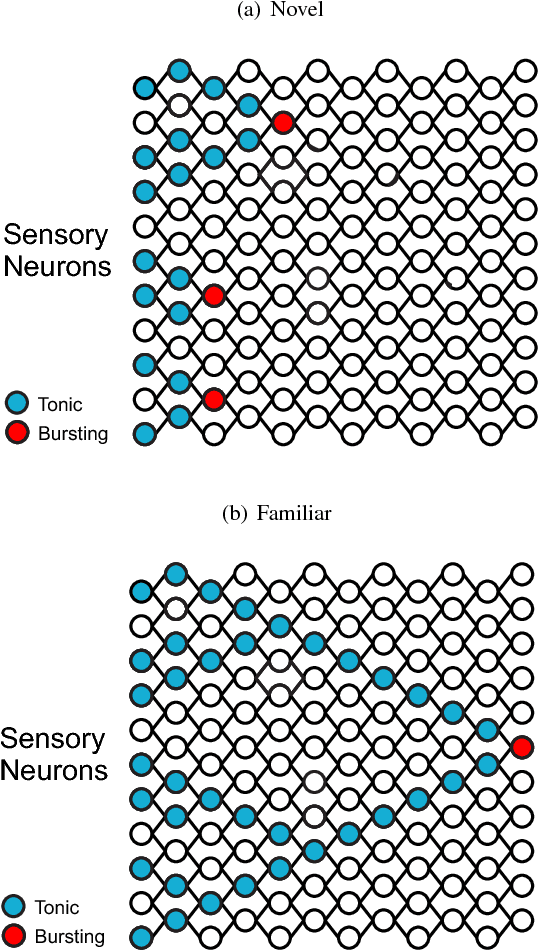

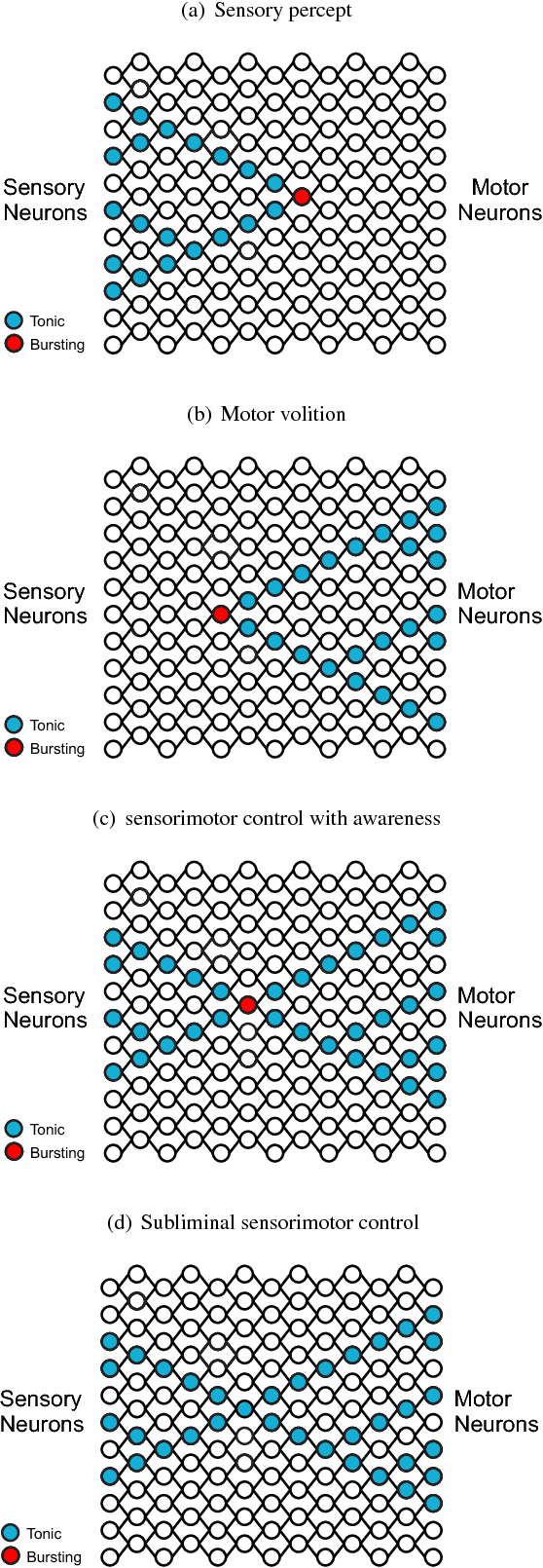

This paper proposes a framework for the biological learning mechanism as a general learning system. The proposal is as follows. The bursting and tonic modes of firing patterns found in many neuron types in the brain correspond to two separate modes of information processing, with one mode resulting in awareness, and another mode being subliminal. In such a coding scheme, a neuron in bursting state codes for the highest level of perceptual abstraction representing a pattern of sensory stimuli, or volitional abstraction representing a pattern of muscle contraction sequences. Within the 50-250 ms minimum integration time of experience, the bursting neurons form synchrony ensembles to allow for binding of related percepts. The degree which different bursting neurons can be merged into the same synchrony ensemble depends on the underlying cortical connections that represent the degree of perceptual similarity. These synchrony ensembles compete for selective attention to remain active. The dominant synchrony ensemble triggers episodic memory recall in the hippocampus, while forming new episodic memory with current sensory stimuli, resulting in a stream of thoughts. Neuromodulation modulates both top-down selection of synchrony ensembles, and memory formation. Episodic memory stored in the hippocampus is transferred to semantic and procedural memory in the cortex during rapid eye movement sleep, by updating cortical neuron synaptic weights with spike timing dependent plasticity. With the update of synaptic weights, new neurons become bursting while previous bursting neurons become tonic, allowing bursting neurons to move up to a higher level of perceptual abstraction. Finally, the proposed learning mechanism is compared with the back-propagation algorithm used in deep neural networks, and a proposal of how the credit assignment problem can be addressed by the current proposal is presented.