 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Masked Autoencoder Based Network for Indoor Depth Completion
Paper and Code
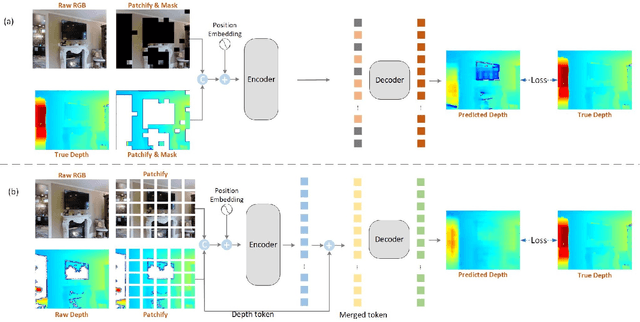
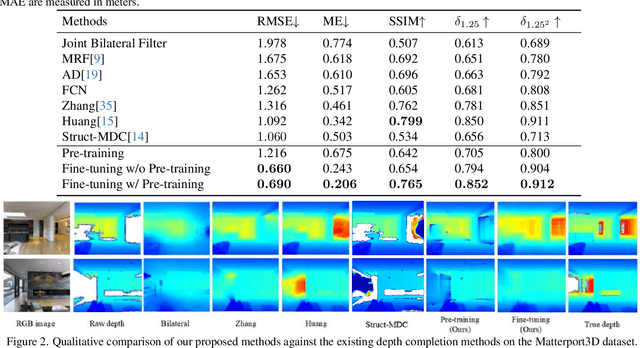
Depth images have a wide range of applications, such as 3D reconstruction, autonomous driving, augmented reality, robot navigation, and scene understanding. Commodity-grade depth cameras are hard to sense depth for bright, glossy, transparent, and distant surfaces. Although existing depth completion methods have achieved remarkable progress, their performance is limited when applied to complex indoor scenarios. To address these problems, we propose a two-step Transformer-based network for indoor depth completion. Unlike existing depth completion approaches, we adopt a self-supervision pre-training encoder based on the masked autoencoder to learn an effective latent representation for the missing depth value; then we propose a decoder based on a token fusion mechanism to complete (i.e., reconstruct) the full depth from the jointly RGB and incomplete depth image. Compared to the existing methods, our proposed network, achieves the state-of-the-art performance on the Matterport3D dataset. In addition, to validate the importance of the depth completion task, we apply our methods to indoor 3D reconstruction. The code, dataset, and demo are available at https://github.com/kailaisun/Indoor-Depth-Completion.