 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Pedestrian Head Tracking: A Benchmark Dataset and an Information Fusion Network
Paper and Code
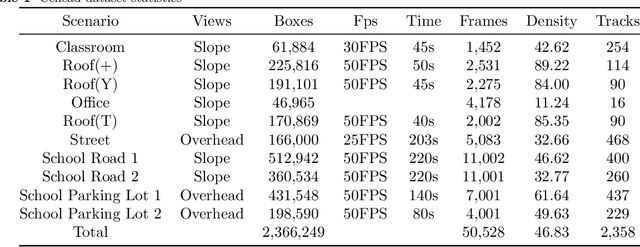


Pedestrian detection and tracking in crowded video sequences have a wide range of applications, including autonomous driving, robot navigation and pedestrian flow surveillance. However, detecting and tracking pedestrians in high-density crowds face many challenges, including intra-class occlusions, complex motions, and diverse poses. Although deep learning models have achieved remarkable progress in head detection, head tracking datasets and methods are extremely lacking. Existing head datasets have limited coverage of complex pedestrian flows and scenes (e.g., pedestrian interactions, occlusions, and object interference). It is of great importance to develop new head tracking datasets and methods. To address these challenges, we present a Chinese Large-scale Cross-scene Pedestrian Head Tracking dataset (Cchead) and a Multi-Source Information Fusion Network (MIFN). Our dataset has features that are of considerable interest, including 10 diverse scenes of 50,528 frames with over 2,366,249 heads and 2,358 tracks annotated. Our dataset contains diverse human moving speeds, directions, and complex crowd pedestrian flows with collision avoidance behaviors. We provide a comprehensive analysis and comparison with existing state-of-the-art (SOTA) algorithms. Moreover, our MIFN is the first end-to-end CNN-based head detection and tracking network that jointly trains RGB frames, pixel-level motion information (optical flow and frame difference maps), depth maps, and density maps in videos. Compared with SOTA pedestrian detection and tracking methods, MIFN achieves superior performance on our Cchead dataset. We believe our datasets and baseline will become valuable resources towards developing pedestrian tracking in dense crowds.