 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Secure Program Partitioning for Smart Contracts with LLM's In-Context Learning
Feb 20, 2025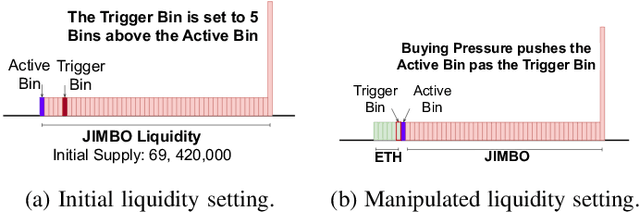
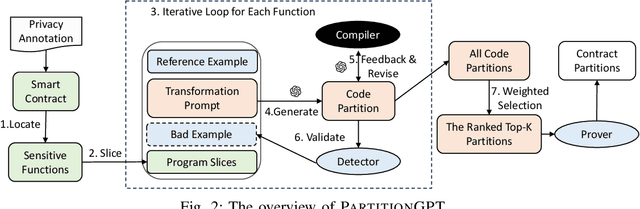

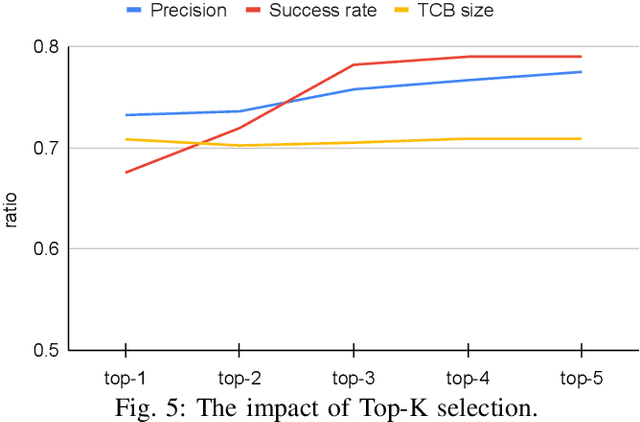
Smart contracts are highly susceptible to manipulation attacks due to the leakage of sensitive information. Addressing manipulation vulnerabilities is particularly challenging because they stem from inherent data confidentiality issues rather than straightforward implementation bugs. To tackle this by preventing sensitive information leakage, we present PartitionGPT, the first LLM-driven approach that combines static analysis with the in-context learning capabilities of large language models (LLMs) to partition smart contracts into privileged and normal codebases, guided by a few annotated sensitive data variables. We evaluated PartitionGPT on 18 annotated smart contracts containing 99 sensitive functions. The results demonstrate that PartitionGPT successfully generates compilable, and verified partitions for 78% of the sensitive functions while reducing approximately 30% code compared to function-level partitioning approach. Furthermore, we evaluated PartitionGPT on nine real-world manipulation attacks that lead to a total loss of 25 million dollars, PartitionGPT effectively prevents eight cases, highlighting its potential for broad applicability and the necessity for secure program partitioning during smart contract development to diminish manipulation vulnerabilities.
Do Existing Testing Tools Really Uncover Gender Bias in Text-to-Image Models?
Jan 27, 2025



Text-to-Image (T2I) models have recently gained significant attention due to their ability to generate high-quality images and are consequently used in a wide range of applications. However, there are concerns about the gender bias of these models. Previous studies have shown that T2I models can perpetuate or even amplify gender stereotypes when provided with neutral text prompts. Researchers have proposed automated gender bias uncovering detectors for T2I models, but a crucial gap exists: no existing work comprehensively compares the various detectors and understands how the gender bias detected by them deviates from the actual situation. This study addresses this gap by validating previous gender bias detectors using a manually labeled dataset and comparing how the bias identified by various detectors deviates from the actual bias in T2I models, as verified by manual confirmation. We create a dataset consisting of 6,000 images generated from three cutting-edge T2I models: Stable Diffusion XL, Stable Diffusion 3, and Dreamlike Photoreal 2.0. During the human-labeling process, we find that all three T2I models generate a portion (12.48% on average) of low-quality images (e.g., generate images with no face present), where human annotators cannot determine the gender of the person. Our analysis reveals that all three T2I models show a preference for generating male images, with SDXL being the most biased. Additionally, images generated using prompts containing professional descriptions (e.g., lawyer or doctor) show the most bias. We evaluate seven gender bias detectors and find that none fully capture the actual level of bias in T2I models, with some detectors overestimating bias by up to 26.95%. We further investigate the causes of inaccurate estimations, highlighting the limitations of detectors in dealing with low-quality images. Based on our findings, we propose an enhanced detector...