 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Adaptive and Differentiable Regression
Aug 14, 2023
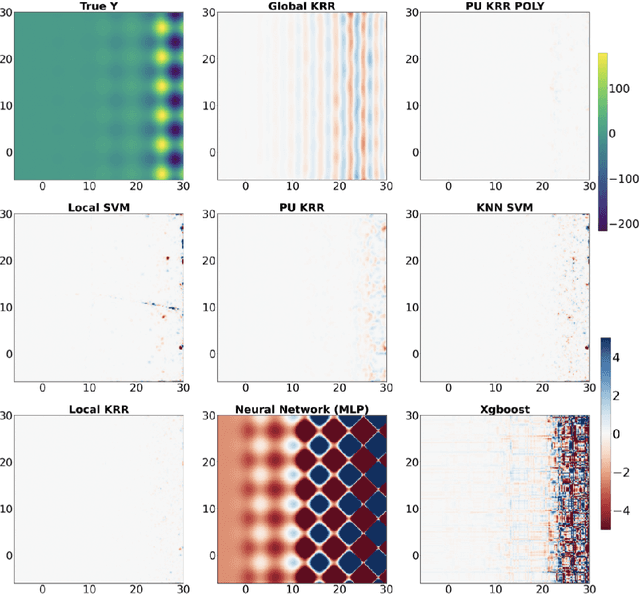

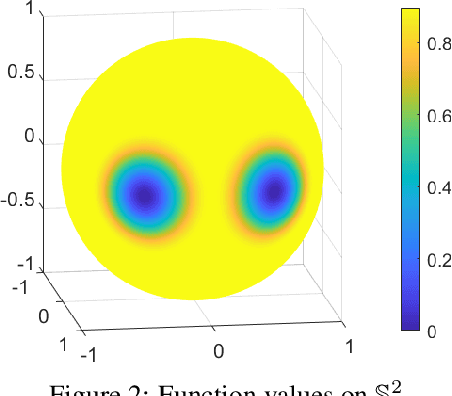
Over-parameterized models like deep nets and random forests have become very popular in machine learning. However, the natural goals of continuity and differentiability, common in regression models, are now often ignored in modern overparametrized, locally-adaptive models. We propose a general framework to construct a global continuous and differentiable model based on a weighted average of locally learned models in corresponding local regions. This model is competitive in dealing with data with different densities or scales of function values in different local regions. We demonstrate that when we mix kernel ridge and polynomial regression terms in the local models, and stitch them together continuously, we achieve faster statistical convergence in theory and improved performance in various practical settings.
Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies
Aug 27, 2021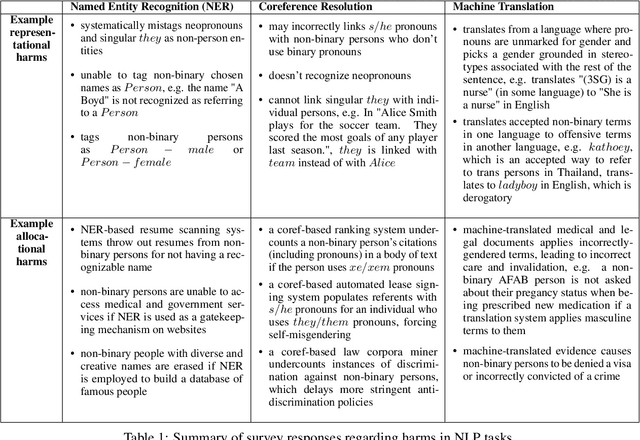
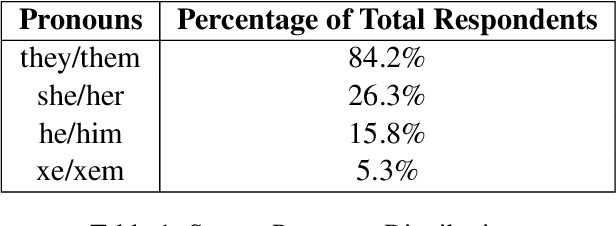
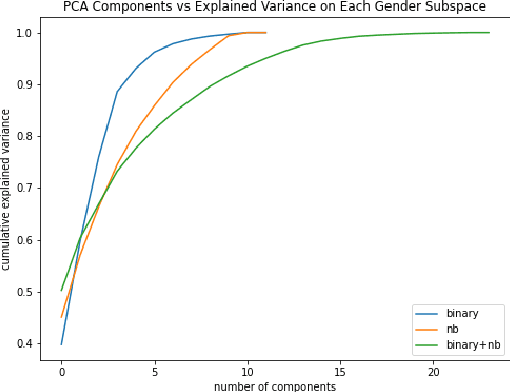

Gender is widely discussed in the context of language tasks and when examining the stereotypes propagated by language models. However, current discussions primarily treat gender as binary, which can perpetuate harms such as the cyclical erasure of non-binary gender identities. These harms are driven by model and dataset biases, which are consequences of the non-recognition and lack of understanding of non-binary genders in society. In this paper, we explain the complexity of gender and language around it, and survey non-binary persons to understand harms associated with the treatment of gender as binary in English language technologies. We also detail how current language representations (e.g., GloVe, BERT) capture and perpetuate these harms and related challenges that need to be acknowledged and addressed for representations to equitably encode gender information.
OSCaR: Orthogonal Subspace Correction and Rectification of Biases in Word Embeddings
Jun 30, 2020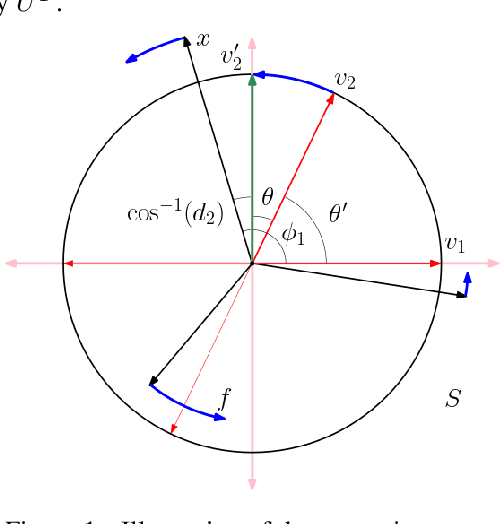
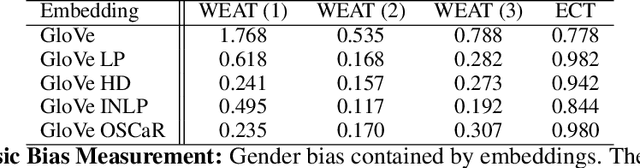
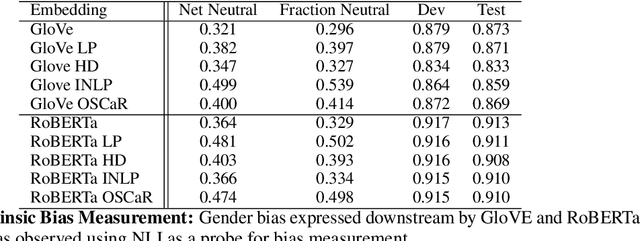

Language representations are known to carry stereotypical biases and, as a result, lead to biased predictions in downstream tasks. While existing methods are effective at mitigating biases by linear projection, such methods are too aggressive: they not only remove bias, but also erase valuable information from word embeddings. We develop new measures for evaluating specific information retention that demonstrate the tradeoff between bias removal and information retention. To address this challenge, we propose OSCaR (Orthogonal Subspace Correction and Rectification), a bias-mitigating method that focuses on disentangling biased associations between concepts instead of removing concepts wholesale. Our experiments on gender biases show that OSCaR is a well-balanced approach that ensures that semantic information is retained in the embeddings and bias is also effectively mitigated.