 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLike a bilingual baby: The advantage of visually grounding a bilingual language model
Paper and Code
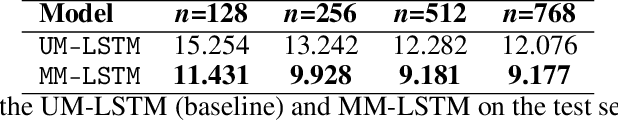
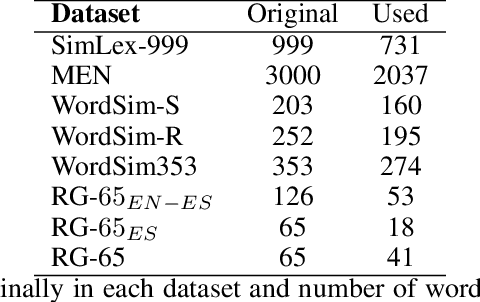
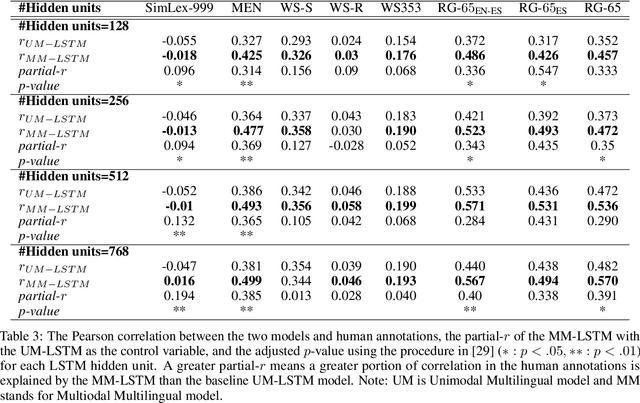

Unlike most neural language models, humans learn language in a rich, multi-sensory and, often, multi-lingual environment. Current language models typically fail to fully capture the complexities of multilingual language use. We train an LSTM language model on images and captions in English and Spanish from MS-COCO-ES. We find that the visual grounding improves the model's understanding of semantic similarity both within and across languages and improves perplexity. However, we find no significant advantage of visual grounding for abstract words. Our results provide additional evidence of the advantages of visually grounded language models and point to the need for more naturalistic language data from multilingual speakers and multilingual datasets with perceptual grounding.