 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyglot-Lion: Efficient Multilingual ASR for Singapore via Balanced Fine-Tuning of Qwen3-ASR
Mar 17, 2026We present Polyglot-Lion, a family of compact multilingual automatic speech recognition (ASR) models tailored for the linguistic landscape of Singapore, covering English, Mandarin, Tamil, and Malay. Our models are obtained by fine-tuning Qwen3-ASR-0.6B and Qwen3-ASR-1.7B exclusively on publicly available speech corpora, using a balanced sampling strategy that equalizes the number of training utterances per language and deliberately omits language-tag conditioning so that the model learns to identify languages implicitly from audio. On 12 benchmarks spanning the four target languages, Polyglot-Lion-1.7B achieves an average error rate of 14.85, competitive with MERaLiON-2-10B-ASR (14.32) - a model 6x larger - while incurring a training cost of \$81 on a single RTX PRO 6000 GPU compared to \$18,862 for the 128-GPU baseline. Inference throughput is approximately 20x faster than MERaLiON at 0.10 s/sample versus 2.02 s/sample. These results demonstrate that linguistically balanced fine-tuning of moderate-scale pretrained models can yield deployment-ready multilingual ASR at a fraction of the cost of larger specialist systems.
Selective Steering: Norm-Preserving Control Through Discriminative Layer Selection
Jan 27, 2026Despite significant progress in alignment, large language models (LLMs) remain vulnerable to adversarial attacks that elicit harmful behaviors. Activation steering techniques offer a promising inference-time intervention approach, but existing methods suffer from critical limitations: activation addition requires careful coefficient tuning and is sensitive to layer-specific norm variations, while directional ablation provides only binary control. Recent work on Angular Steering introduces continuous control via rotation in a 2D subspace, but its practical implementation violates norm preservation, causing distribution shift and generation collapse, particularly in models below 7B parameters. We propose Selective Steering, which addresses these limitations through two key innovations: (1) a mathematically rigorous norm-preserving rotation formulation that maintains activation distribution integrity, and (2) discriminative layer selection that applies steering only where feature representations exhibit opposite-signed class alignment. Experiments across nine models demonstrate that Selective Steering achieves 5.5x higher attack success rates than prior methods while maintaining zero perplexity violations and approximately 100\% capability retention on standard benchmarks. Our approach provides a principled, efficient framework for controllable and stable LLM behavior modification. Code: https://github.com/knoveleng/steering
RedBench: A Universal Dataset for Comprehensive Red Teaming of Large Language Models
Jan 07, 2026As large language models (LLMs) become integral to safety-critical applications, ensuring their robustness against adversarial prompts is paramount. However, existing red teaming datasets suffer from inconsistent risk categorizations, limited domain coverage, and outdated evaluations, hindering systematic vulnerability assessments. To address these challenges, we introduce RedBench, a universal dataset aggregating 37 benchmark datasets from leading conferences and repositories, comprising 29,362 samples across attack and refusal prompts. RedBench employs a standardized taxonomy with 22 risk categories and 19 domains, enabling consistent and comprehensive evaluations of LLM vulnerabilities. We provide a detailed analysis of existing datasets, establish baselines for modern LLMs, and open-source the dataset and evaluation code. Our contributions facilitate robust comparisons, foster future research, and promote the development of secure and reliable LLMs for real-world deployment. Code: https://github.com/knoveleng/redeval
RainbowPlus: Enhancing Adversarial Prompt Generation via Evolutionary Quality-Diversity Search
Apr 21, 2025Large Language Models (LLMs) exhibit remarkable capabilities but are susceptible to adversarial prompts that exploit vulnerabilities to produce unsafe or biased outputs. Existing red-teaming methods often face scalability challenges, resource-intensive requirements, or limited diversity in attack strategies. We propose RainbowPlus, a novel red-teaming framework rooted in evolutionary computation, enhancing adversarial prompt generation through an adaptive quality-diversity (QD) search that extends classical evolutionary algorithms like MAP-Elites with innovations tailored for language models. By employing a multi-element archive to store diverse high-quality prompts and a comprehensive fitness function to evaluate multiple prompts concurrently, RainbowPlus overcomes the constraints of single-prompt archives and pairwise comparisons in prior QD methods like Rainbow Teaming. Experiments comparing RainbowPlus to QD methods across six benchmark datasets and four open-source LLMs demonstrate superior attack success rate (ASR) and diversity (Diverse-Score $\approx 0.84$), generating up to 100 times more unique prompts (e.g., 10,418 vs. 100 for Ministral-8B-Instruct-2410). Against nine state-of-the-art methods on the HarmBench dataset with twelve LLMs (ten open-source, two closed-source), RainbowPlus achieves an average ASR of 81.1%, surpassing AutoDAN-Turbo by 3.9%, and is 9 times faster (1.45 vs. 13.50 hours). Our open-source implementation fosters further advancements in LLM safety, offering a scalable tool for vulnerability assessment. Code and resources are publicly available at https://github.com/knoveleng/rainbowplus, supporting reproducibility and future research in LLM red-teaming.
Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't
Mar 20, 2025



Enhancing the reasoning capabilities of large language models (LLMs) typically relies on massive computational resources and extensive datasets, limiting accessibility for resource-constrained settings. Our study investigates the potential of reinforcement learning (RL) to improve reasoning in small LLMs, focusing on a 1.5-billion-parameter model, DeepSeek-R1-Distill-Qwen-1.5B, under strict constraints: training on 4 NVIDIA A40 GPUs (48 GB VRAM each) within 24 hours. Adapting the Group Relative Policy Optimization (GRPO) algorithm and curating a compact, high-quality mathematical reasoning dataset, we conducted three experiments to explore model behavior and performance. Our results demonstrate rapid reasoning gains - e.g., AMC23 accuracy rising from 63% to 80% and AIME24 reaching 46.7%, surpassing o1-preview - using only 7,000 samples and a $42 training cost, compared to thousands of dollars for baseline models. However, challenges such as optimization instability and length constraints emerged with prolonged training. These findings highlight the efficacy of RL-based fine-tuning for small LLMs, offering a cost-effective alternative to large-scale approaches. We release our code and datasets as open-source resources, providing insights into trade-offs and laying a foundation for scalable, reasoning-capable LLMs in resource-limited environments. All are available at https://github.com/knoveleng/open-rs.
MoD: A Distribution-Based Approach for Merging Large Language Models
Nov 01, 2024



Large language models (LLMs) have enabled the development of numerous specialized, task-specific variants. However, the maintenance and deployment of these individual models present substantial challenges in terms of resource utilization and operational efficiency. In this work, we propose the \textit{Mixture of Distributions (MoD)} framework, a novel approach for merging LLMs that operates directly on their output probability distributions, rather than on model weights. Unlike traditional weight-averaging methods, MoD effectively preserves the specialized capabilities of individual models while enabling efficient knowledge sharing across tasks. Through extensive experimentation on mathematical reasoning benchmarks using Qwen2.5 models, we demonstrate that MoD significantly outperforms existing model merging techniques across multiple benchmarks. All code, data, and experimental materials are published at https://github.com/knovel-eng/mod.
wav2graph: A Framework for Supervised Learning Knowledge Graph from Speech
Aug 08, 2024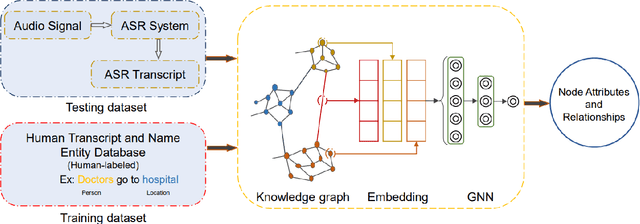
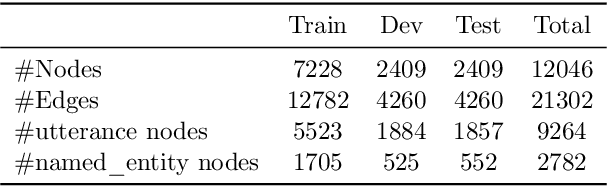
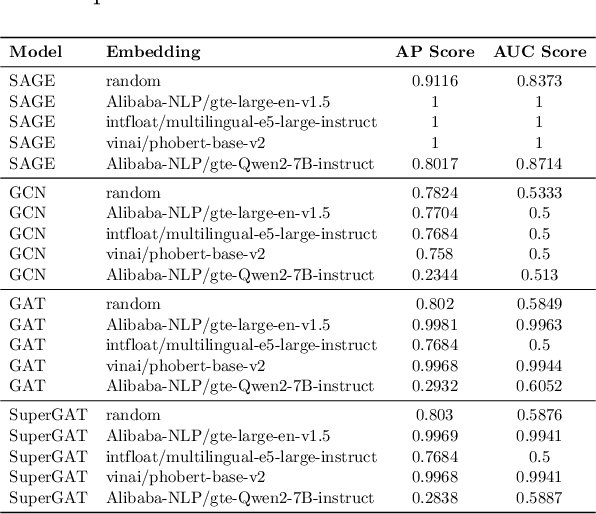
Knowledge graphs (KGs) enhance the performance of large language models (LLMs) and search engines by providing structured, interconnected data that improves reasoning and context-awareness. However, KGs only focus on text data, thereby neglecting other modalities such as speech. In this work, we introduce wav2graph, the first framework for supervised learning knowledge graph from speech data. Our pipeline are straightforward: (1) constructing a KG based on transcribed spoken utterances and a named entity database, (2) converting KG into embedding vectors, and (3) training graph neural networks (GNNs) for node classification and link prediction tasks. Through extensive experiments conducted in inductive and transductive learning contexts using state-of-the-art GNN models, we provide baseline results and error analysis for node classification and link prediction tasks on human transcripts and automatic speech recognition (ASR) transcripts, including evaluations using both encoder-based and decoder-based node embeddings, as well as monolingual and multilingual acoustic pre-trained models. All related code, data, and models are published online.