 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Steering: Norm-Preserving Control Through Discriminative Layer Selection
Jan 27, 2026Despite significant progress in alignment, large language models (LLMs) remain vulnerable to adversarial attacks that elicit harmful behaviors. Activation steering techniques offer a promising inference-time intervention approach, but existing methods suffer from critical limitations: activation addition requires careful coefficient tuning and is sensitive to layer-specific norm variations, while directional ablation provides only binary control. Recent work on Angular Steering introduces continuous control via rotation in a 2D subspace, but its practical implementation violates norm preservation, causing distribution shift and generation collapse, particularly in models below 7B parameters. We propose Selective Steering, which addresses these limitations through two key innovations: (1) a mathematically rigorous norm-preserving rotation formulation that maintains activation distribution integrity, and (2) discriminative layer selection that applies steering only where feature representations exhibit opposite-signed class alignment. Experiments across nine models demonstrate that Selective Steering achieves 5.5x higher attack success rates than prior methods while maintaining zero perplexity violations and approximately 100\% capability retention on standard benchmarks. Our approach provides a principled, efficient framework for controllable and stable LLM behavior modification. Code: https://github.com/knoveleng/steering
RedBench: A Universal Dataset for Comprehensive Red Teaming of Large Language Models
Jan 07, 2026As large language models (LLMs) become integral to safety-critical applications, ensuring their robustness against adversarial prompts is paramount. However, existing red teaming datasets suffer from inconsistent risk categorizations, limited domain coverage, and outdated evaluations, hindering systematic vulnerability assessments. To address these challenges, we introduce RedBench, a universal dataset aggregating 37 benchmark datasets from leading conferences and repositories, comprising 29,362 samples across attack and refusal prompts. RedBench employs a standardized taxonomy with 22 risk categories and 19 domains, enabling consistent and comprehensive evaluations of LLM vulnerabilities. We provide a detailed analysis of existing datasets, establish baselines for modern LLMs, and open-source the dataset and evaluation code. Our contributions facilitate robust comparisons, foster future research, and promote the development of secure and reliable LLMs for real-world deployment. Code: https://github.com/knoveleng/redeval
S-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025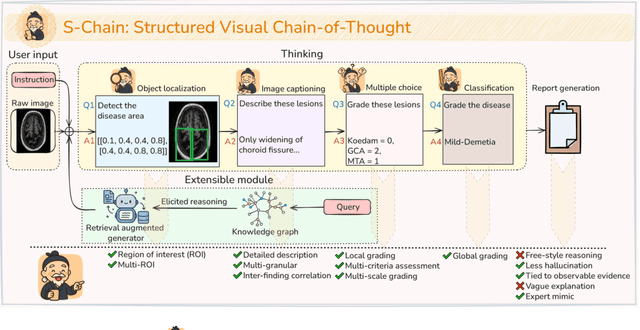
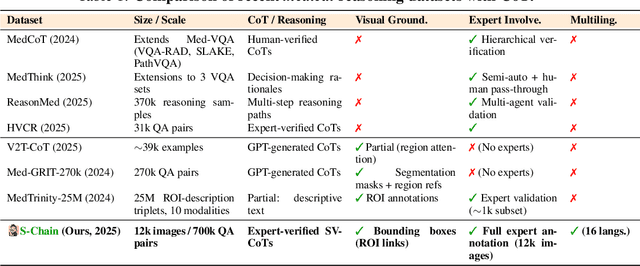
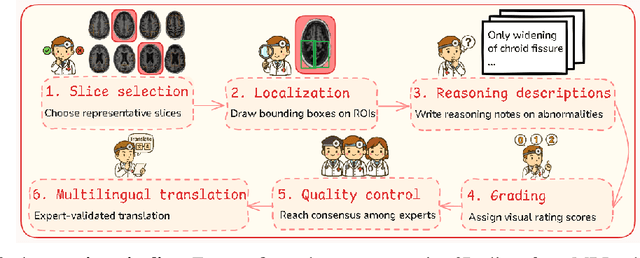
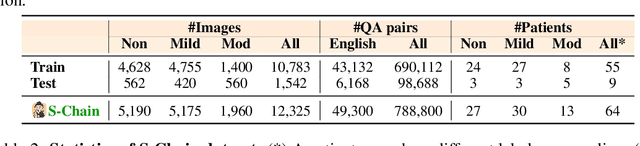
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
Multimodal Chain of Continuous Thought for Latent-Space Reasoning in Vision-Language Models
Aug 18, 2025Many reasoning techniques for large multimodal models adapt language model approaches, such as Chain-of-Thought (CoT) prompting, which express reasoning as word sequences. While effective for text, these methods are suboptimal for multimodal contexts, struggling to align audio, visual, and textual information dynamically. To explore an alternative paradigm, we propose the Multimodal Chain of Continuous Thought (MCOUT), which enables reasoning directly in a joint latent space rather than in natural language. In MCOUT, the reasoning state is represented as a continuous hidden vector, iteratively refined and aligned with visual and textual embeddings, inspired by human reflective cognition. We develop two variants: MCOUT-Base, which reuses the language model`s last hidden state as the continuous thought for iterative reasoning, and MCOUT-Multi, which integrates multimodal latent attention to strengthen cross-modal alignment between visual and textual features. Experiments on benchmarks including MMMU, ScienceQA, and MMStar show that MCOUT consistently improves multimodal reasoning, yielding up to 8.23% accuracy gains over strong baselines and improving BLEU scores up to 8.27% across multiple-choice and open-ended tasks. These findings highlight latent continuous reasoning as a promising direction for advancing LMMs beyond language-bound CoT, offering a scalable framework for human-like reflective multimodal inference. Code is available at https://github.com/Hanhpt23/OmniMod.
Repeton: Structured Bug Repair with ReAct-Guided Patch-and-Test Cycles
Jun 09, 2025Large Language Models (LLMs) have shown strong capabilities in code generation and comprehension, yet their application to complex software engineering tasks often suffers from low precision and limited interpretability. We present Repeton, a fully open-source framework that leverages LLMs for precise and automated code manipulation in real-world Git repositories. Rather than generating holistic fixes, Repeton operates through a structured patch-and-test pipeline: it iteratively diagnoses issues, proposes code changes, and validates each patch through automated testing. This stepwise process is guided by lightweight heuristics and development tools, avoiding reliance on embedding-based retrieval systems. Evaluated on the SWE-bench Lite benchmark, our method shows good performance compared to RAG-based methods in both patch validity and interpretability. By decomposing software engineering tasks into modular, verifiable stages, Repeton provides a practical path toward scalable and transparent autonomous debugging.
RARL: Improving Medical VLM Reasoning and Generalization with Reinforcement Learning and LoRA under Data and Hardware Constraints
Jun 07, 2025



The growing integration of vision-language models (VLMs) in medical applications offers promising support for diagnostic reasoning. However, current medical VLMs often face limitations in generalization, transparency, and computational efficiency-barriers that hinder deployment in real-world, resource-constrained settings. To address these challenges, we propose a Reasoning-Aware Reinforcement Learning framework, \textbf{RARL}, that enhances the reasoning capabilities of medical VLMs while remaining efficient and adaptable to low-resource environments. Our approach fine-tunes a lightweight base model, Qwen2-VL-2B-Instruct, using Low-Rank Adaptation and custom reward functions that jointly consider diagnostic accuracy and reasoning quality. Training is performed on a single NVIDIA A100-PCIE-40GB GPU, demonstrating the feasibility of deploying such models in constrained environments. We evaluate the model using an LLM-as-judge framework that scores both correctness and explanation quality. Experimental results show that RARL significantly improves VLM performance in medical image analysis and clinical reasoning, outperforming supervised fine-tuning on reasoning-focused tasks by approximately 7.78%, while requiring fewer computational resources. Additionally, we demonstrate the generalization capabilities of our approach on unseen datasets, achieving around 27% improved performance compared to supervised fine-tuning and about 4% over traditional RL fine-tuning. Our experiments also illustrate that diversity prompting during training and reasoning prompting during inference are crucial for enhancing VLM performance. Our findings highlight the potential of reasoning-guided learning and reasoning prompting to steer medical VLMs toward more transparent, accurate, and resource-efficient clinical decision-making. Code and data are publicly available.
IQBench: How "Smart'' Are Vision-Language Models? A Study with Human IQ Tests
May 17, 2025Although large Vision-Language Models (VLMs) have demonstrated remarkable performance in a wide range of multimodal tasks, their true reasoning capabilities on human IQ tests remain underexplored. To advance research on the fluid intelligence of VLMs, we introduce **IQBench**, a new benchmark designed to evaluate VLMs on standardized visual IQ tests. We focus on evaluating the reasoning capabilities of VLMs, which we argue are more important than the accuracy of the final prediction. **Our benchmark is visually centric, minimizing the dependence on unnecessary textual content**, thus encouraging models to derive answers primarily from image-based information rather than learned textual knowledge. To this end, we manually collected and annotated 500 visual IQ questions to **prevent unintentional data leakage during training**. Unlike prior work that focuses primarily on the accuracy of the final answer, we evaluate the reasoning ability of the models by assessing their explanations and the patterns used to solve each problem, along with the accuracy of the final prediction and human evaluation. Our experiments show that there are substantial performance disparities between tasks, with models such as `o4-mini`, `gemini-2.5-flash`, and `claude-3.7-sonnet` achieving the highest average accuracies of 0.615, 0.578, and 0.548, respectively. However, all models struggle with 3D spatial and anagram reasoning tasks, highlighting significant limitations in current VLMs' general reasoning abilities. In terms of reasoning scores, `o4-mini`, `gemini-2.5-flash`, and `claude-3.7-sonnet` achieved top averages of 0.696, 0.586, and 0.516, respectively. These results highlight inconsistencies between the reasoning processes of the models and their final answers, emphasizing the importance of evaluating the accuracy of the reasoning in addition to the final predictions.
RainbowPlus: Enhancing Adversarial Prompt Generation via Evolutionary Quality-Diversity Search
Apr 21, 2025Large Language Models (LLMs) exhibit remarkable capabilities but are susceptible to adversarial prompts that exploit vulnerabilities to produce unsafe or biased outputs. Existing red-teaming methods often face scalability challenges, resource-intensive requirements, or limited diversity in attack strategies. We propose RainbowPlus, a novel red-teaming framework rooted in evolutionary computation, enhancing adversarial prompt generation through an adaptive quality-diversity (QD) search that extends classical evolutionary algorithms like MAP-Elites with innovations tailored for language models. By employing a multi-element archive to store diverse high-quality prompts and a comprehensive fitness function to evaluate multiple prompts concurrently, RainbowPlus overcomes the constraints of single-prompt archives and pairwise comparisons in prior QD methods like Rainbow Teaming. Experiments comparing RainbowPlus to QD methods across six benchmark datasets and four open-source LLMs demonstrate superior attack success rate (ASR) and diversity (Diverse-Score $\approx 0.84$), generating up to 100 times more unique prompts (e.g., 10,418 vs. 100 for Ministral-8B-Instruct-2410). Against nine state-of-the-art methods on the HarmBench dataset with twelve LLMs (ten open-source, two closed-source), RainbowPlus achieves an average ASR of 81.1%, surpassing AutoDAN-Turbo by 3.9%, and is 9 times faster (1.45 vs. 13.50 hours). Our open-source implementation fosters further advancements in LLM safety, offering a scalable tool for vulnerability assessment. Code and resources are publicly available at https://github.com/knoveleng/rainbowplus, supporting reproducibility and future research in LLM red-teaming.
SilVar-Med: A Speech-Driven Visual Language Model for Explainable Abnormality Detection in Medical Imaging
Apr 14, 2025Medical Visual Language Models have shown great potential in various healthcare applications, including medical image captioning and diagnostic assistance. However, most existing models rely on text-based instructions, limiting their usability in real-world clinical environments especially in scenarios such as surgery, text-based interaction is often impractical for physicians. In addition, current medical image analysis models typically lack comprehensive reasoning behind their predictions, which reduces their reliability for clinical decision-making. Given that medical diagnosis errors can have life-changing consequences, there is a critical need for interpretable and rational medical assistance. To address these challenges, we introduce an end-to-end speech-driven medical VLM, SilVar-Med, a multimodal medical image assistant that integrates speech interaction with VLMs, pioneering the task of voice-based communication for medical image analysis. In addition, we focus on the interpretation of the reasoning behind each prediction of medical abnormalities with a proposed reasoning dataset. Through extensive experiments, we demonstrate a proof-of-concept study for reasoning-driven medical image interpretation with end-to-end speech interaction. We believe this work will advance the field of medical AI by fostering more transparent, interactive, and clinically viable diagnostic support systems. Our code and dataset are publicly available at SiVar-Med.
MultiMed-ST: Large-scale Many-to-many Multilingual Medical Speech Translation
Apr 04, 2025Multilingual speech translation (ST) in the medical domain enhances patient care by enabling efficient communication across language barriers, alleviating specialized workforce shortages, and facilitating improved diagnosis and treatment, particularly during pandemics. In this work, we present the first systematic study on medical ST, to our best knowledge, by releasing MultiMed-ST, a large-scale ST dataset for the medical domain, spanning all translation directions in five languages: Vietnamese, English, German, French, Traditional Chinese and Simplified Chinese, together with the models. With 290,000 samples, our dataset is the largest medical machine translation (MT) dataset and the largest many-to-many multilingual ST among all domains. Secondly, we present the most extensive analysis study in ST research to date, including: empirical baselines, bilingual-multilingual comparative study, end-to-end vs. cascaded comparative study, task-specific vs. multi-task sequence-to-sequence (seq2seq) comparative study, code-switch analysis, and quantitative-qualitative error analysis. All code, data, and models are available online: https://github.com/leduckhai/MultiMed-ST.