 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Audio to Audio Emotion Transfer With Speaker Disentanglement
Paper and Code

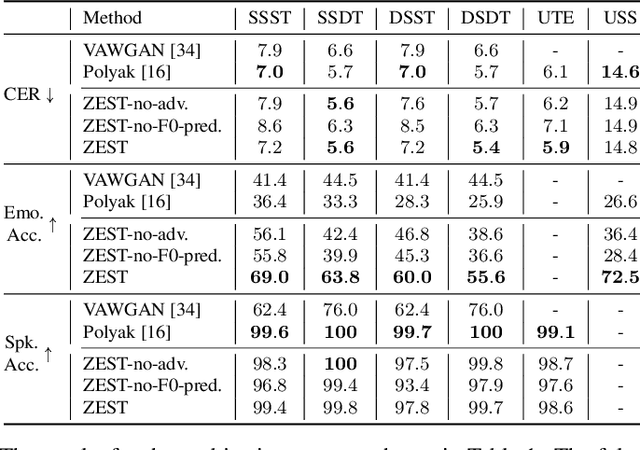


The problem of audio-to-audio (A2A) style transfer involves replacing the style features of the source audio with those from the target audio while preserving the content related attributes of the source audio. In this paper, we propose an efficient approach, termed as Zero-shot Emotion Style Transfer (ZEST), that allows the transfer of emotional content present in the given source audio with the one embedded in the target audio while retaining the speaker and speech content from the source. The proposed system builds upon decomposing speech into semantic tokens, speaker representations and emotion embeddings. Using these factors, we propose a framework to reconstruct the pitch contour of the given speech signal and train a decoder that reconstructs the speech signal. The model is trained using a self-supervision based reconstruction loss. During conversion, the emotion embedding is alone derived from the target audio, while rest of the factors are derived from the source audio. In our experiments, we show that, even without using parallel training data or labels from the source or target audio, we illustrate zero shot emotion transfer capabilities of the proposed ZEST model using objective and subjective quality evaluations.