 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Understanding on Conceptual Abstraction Benchmarks
Paper and Code
Jun 28, 2022

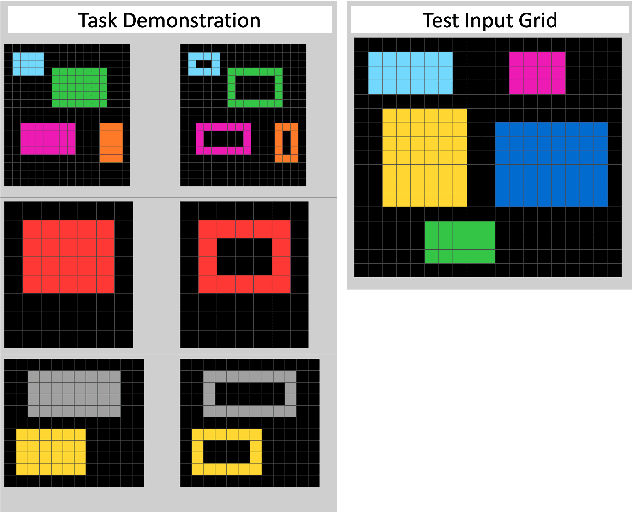

A long-held objective in AI is to build systems that understand concepts in a humanlike way. Setting aside the difficulty of building such a system, even trying to evaluate one is a challenge, due to present-day AI's relative opacity and its proclivity for finding shortcut solutions. This is exacerbated by humans' tendency to anthropomorphize, assuming that a system that can recognize one instance of a concept must also understand other instances, as a human would. In this paper, we argue that understanding a concept requires the ability to use it in varied contexts. Accordingly, we propose systematic evaluations centered around concepts, by probing a system's ability to use a given concept in many different instantiations. We present case studies of such an evaluations on two domains -- RAVEN (inspired by Raven's Progressive Matrices) and the Abstraction and Reasoning Corpus (ARC) -- that have been used to develop and assess abstraction abilities in AI systems. Our concept-based approach to evaluation reveals information about AI systems that conventional test sets would have left hidden.