 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ConceptARC Benchmark: Evaluating Understanding and Generalization in the ARC Domain
May 11, 2023



The abilities to form and abstract concepts is key to human intelligence, but such abilities remain lacking in state-of-the-art AI systems. There has been substantial research on conceptual abstraction in AI, particularly using idealized domains such as Raven's Progressive Matrices and Bongard problems, but even when AI systems succeed on such problems, the systems are rarely evaluated in depth to see if they have actually grasped the concepts they are meant to capture. In this paper we describe an in-depth evaluation benchmark for the Abstraction and Reasoning Corpus (ARC), a collection of few-shot abstraction and analogy problems developed by Chollet [2019]. In particular, we describe ConceptARC, a new, publicly available benchmark in the ARC domain that systematically assesses abstraction and generalization abilities on a number of basic spatial and semantic concepts. ConceptARC differs from the original ARC dataset in that it is specifically organized around "concept groups" -- sets of problems that focus on specific concepts and that are vary in complexity and level of abstraction. We report results on testing humans on this benchmark as well as three machine solvers: the top two programs from a 2021 ARC competition and OpenAI's GPT-4. Our results show that humans substantially outperform the machine solvers on this benchmark, showing abilities to abstract and generalize concepts that are not yet captured by AI systems. We believe that this benchmark will spur improvements in the development of AI systems for conceptual abstraction and in the effective evaluation of such systems.
Evaluating Understanding on Conceptual Abstraction Benchmarks
Jun 28, 2022

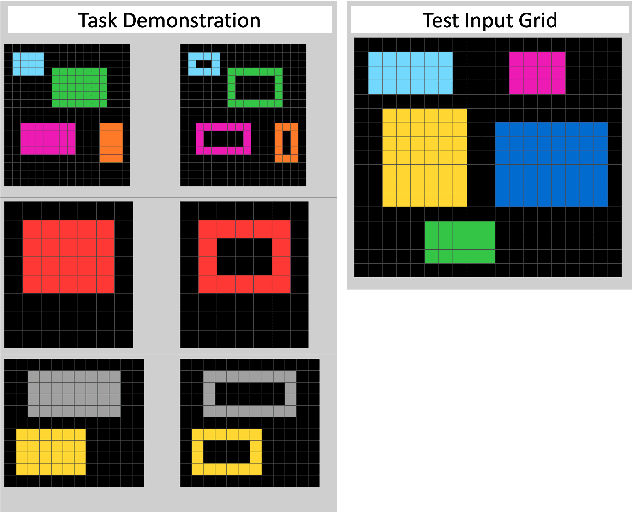

A long-held objective in AI is to build systems that understand concepts in a humanlike way. Setting aside the difficulty of building such a system, even trying to evaluate one is a challenge, due to present-day AI's relative opacity and its proclivity for finding shortcut solutions. This is exacerbated by humans' tendency to anthropomorphize, assuming that a system that can recognize one instance of a concept must also understand other instances, as a human would. In this paper, we argue that understanding a concept requires the ability to use it in varied contexts. Accordingly, we propose systematic evaluations centered around concepts, by probing a system's ability to use a given concept in many different instantiations. We present case studies of such an evaluations on two domains -- RAVEN (inspired by Raven's Progressive Matrices) and the Abstraction and Reasoning Corpus (ARC) -- that have been used to develop and assess abstraction abilities in AI systems. Our concept-based approach to evaluation reveals information about AI systems that conventional test sets would have left hidden.