 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo AI Models Perform Human-like Abstract Reasoning Across Modalities?
Oct 02, 2025



OpenAI's o3-preview reasoning model exceeded human accuracy on the ARC-AGI benchmark, but does that mean state-of-the-art models recognize and reason with the abstractions that the task creators intended? We investigate models' abstraction abilities on ConceptARC. We evaluate models under settings that vary the input modality (textual vs. visual), whether the model is permitted to use external Python tools, and, for reasoning models, the amount of reasoning effort. In addition to measuring output accuracy, we perform fine-grained evaluation of the natural-language rules that models generate to explain their solutions. This dual evaluation lets us assess whether models solve tasks using the abstractions ConceptARC was designed to elicit, rather than relying on surface-level patterns. Our results show that, while some models using text-based representations match human output accuracy, the best models' rules are often based on surface-level ``shortcuts'' and capture intended abstractions far less often than humans. Thus their capabilities for general abstract reasoning may be overestimated by evaluations based on accuracy alone. In the visual modality, AI models' output accuracy drops sharply, yet our rule-level analysis reveals that models might be underestimated, as they still exhibit a substantial share of rules that capture intended abstractions, but are often unable to correctly apply these rules. In short, our results show that models still lag humans in abstract reasoning, and that using accuracy alone to evaluate abstract reasoning on ARC-like tasks may overestimate abstract-reasoning capabilities in textual modalities and underestimate it in visual modalities. We believe that our evaluation framework offers a more faithful picture of multimodal models' abstract reasoning abilities and a more principled way to track progress toward human-like, abstraction-centered intelligence.
Comparing Humans, GPT-4, and GPT-4V On Abstraction and Reasoning Tasks
Nov 26, 2023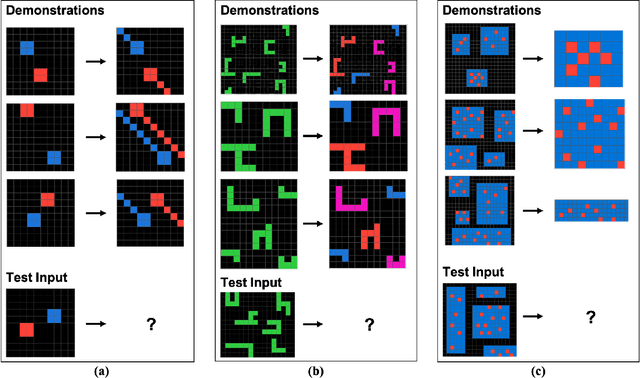
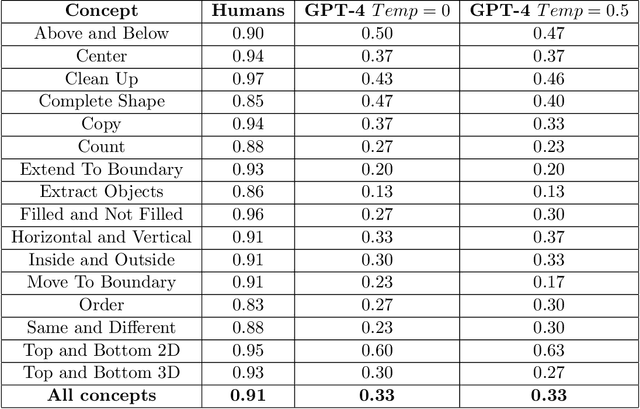

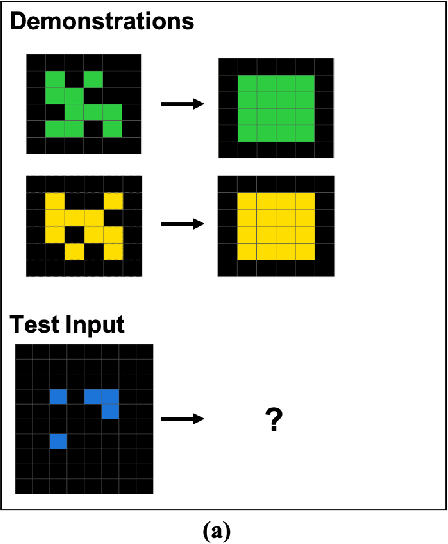
We explore the abstract reasoning abilities of text-only and multimodal versions of GPT-4, using the ConceptARC benchmark [10], which is designed to evaluate robust understanding and reasoning with core-knowledge concepts. We extend the work of Moskvichev et al. [10] by evaluating GPT-4 on more detailed, one-shot prompting (rather than simple, zero-shot prompts) with text versions of ConceptARC tasks, and by evaluating GPT-4V, the multimodal version of GPT-4, on zero- and one-shot prompts using image versions of the simplest tasks. Our experimental results support the conclusion that neither version of GPT-4 has developed robust abstraction abilities at humanlike levels.
Narrative XL: A Large-scale Dataset For Long-Term Memory Models
May 23, 2023Despite their tremendous successes, most large language models do not have any long-term memory mechanisms, which restricts their applications. Overcoming this limitation would not only require changes to the typical transformer architectures or training procedures, but also a dataset on which these new models could be trained and evaluated. We argue that existing resources lack a few key properties, and that at present, there are no naturalistic datasets of sufficient scale to train (and not only evaluate) long-term memory language models. We then present our solution that capitalizes on the advances in short-term memory language models to create such a dataset. Using GPT 3.5, we summarized each scene in 1500 hand-curated books from Project Gutenberg, which resulted in approximately 150 scene-level summaries per book. We then created a number of reading comprehension questions based on these summaries, including three types of multiple-choice scene recognition questions, as well as free-form narrative reconstruction questions. Each book is thus associated with more than 500 reading comprehension questions. Crucially, most questions have a known ``retention demand'', indicating how long-term of a memory is needed to answer it, which should aid long-term memory performance evaluation. We validate our data in three small-scale experiments: one with human labelers, and two with existing language models. We show that our questions 1) adequately represent the source material 2) can be used to diagnose the model's memory capacity 3) are not trivial for modern language models even when the memory demand does not exceed those models' context lengths. Lastly, we provide our code which can be used to further expand the dataset in an automated manner.
The ConceptARC Benchmark: Evaluating Understanding and Generalization in the ARC Domain
May 11, 2023



The abilities to form and abstract concepts is key to human intelligence, but such abilities remain lacking in state-of-the-art AI systems. There has been substantial research on conceptual abstraction in AI, particularly using idealized domains such as Raven's Progressive Matrices and Bongard problems, but even when AI systems succeed on such problems, the systems are rarely evaluated in depth to see if they have actually grasped the concepts they are meant to capture. In this paper we describe an in-depth evaluation benchmark for the Abstraction and Reasoning Corpus (ARC), a collection of few-shot abstraction and analogy problems developed by Chollet [2019]. In particular, we describe ConceptARC, a new, publicly available benchmark in the ARC domain that systematically assesses abstraction and generalization abilities on a number of basic spatial and semantic concepts. ConceptARC differs from the original ARC dataset in that it is specifically organized around "concept groups" -- sets of problems that focus on specific concepts and that are vary in complexity and level of abstraction. We report results on testing humans on this benchmark as well as three machine solvers: the top two programs from a 2021 ARC competition and OpenAI's GPT-4. Our results show that humans substantially outperform the machine solvers on this benchmark, showing abilities to abstract and generalize concepts that are not yet captured by AI systems. We believe that this benchmark will spur improvements in the development of AI systems for conceptual abstraction and in the effective evaluation of such systems.
Updater-Extractor Architecture for Inductive World State Representations
Apr 12, 2021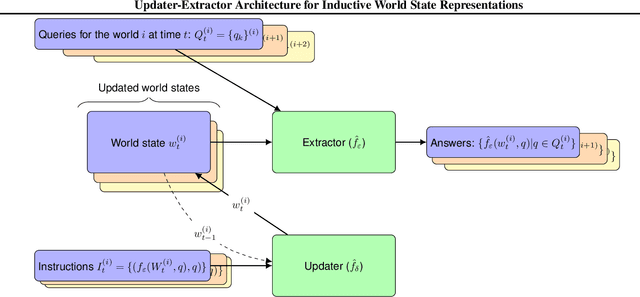

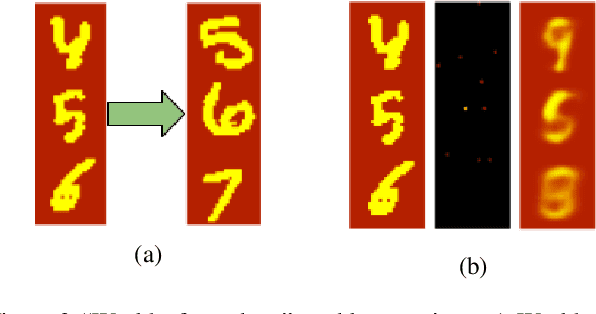
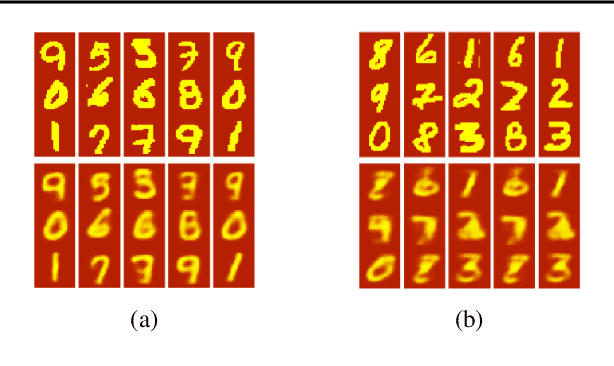
Developing NLP models traditionally involves two stages - training and application. Retention of information acquired after training (at application time) is architecturally limited by the size of the model's context window (in the case of transformers), or by the practical difficulties associated with long sequences (in the case of RNNs). In this paper, we propose a novel transformer-based Updater-Extractor architecture and a training procedure that can work with sequences of arbitrary length and refine its knowledge about the world based on linguistic inputs. We explicitly train the model to incorporate incoming information into its world state representation, obtaining strong inductive generalization and the ability to handle extremely long-range dependencies. We prove a lemma that provides a theoretical basis for our approach. The result also provides insight into success and failure modes of models trained with variants of Truncated Back-Propagation Through Time (such as Transformer XL). Empirically, we investigate the model performance on three different tasks, demonstrating its promise. This preprint is still a work in progress. At present, we focused on easily interpretable tasks, leaving the application of the proposed ideas to practical NLP applications for the future.
Reinforcement Communication Learning in Different Social Network Structures
Jul 19, 2020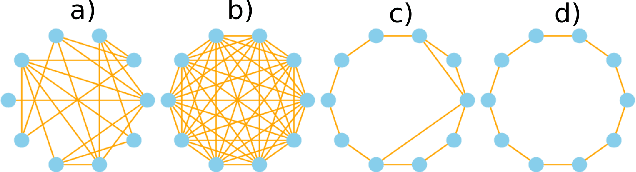
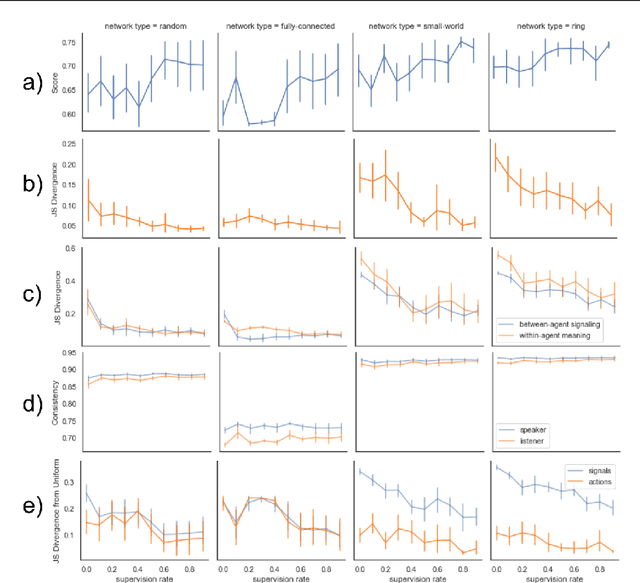
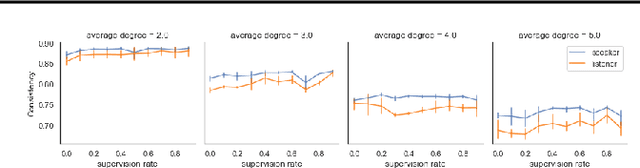
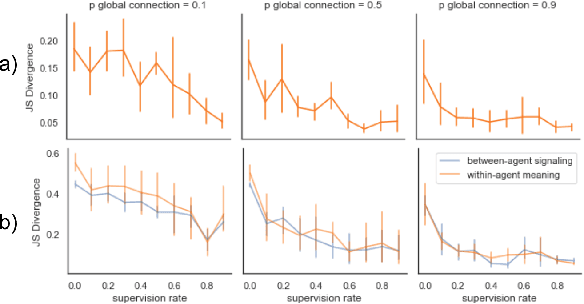
Social network structure is one of the key determinants of human language evolution. Previous work has shown that the network of social interactions shapes decentralized learning in human groups, leading to the emergence of different kinds of communicative conventions. We examined the effects of social network organization on the properties of communication systems emerging in decentralized, multi-agent reinforcement learning communities. We found that the global connectivity of a social network drives the convergence of populations on shared and symmetric communication systems, preventing the agents from forming many local "dialects". Moreover, the agent's degree is inversely related to the consistency of its use of communicative conventions. These results show the importance of the basic properties of social network structure on reinforcement communication learning and suggest a new interpretation of findings on human convergence on word conventions.