Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Humans, GPT-4, and GPT-4V On Abstraction and Reasoning Tasks
Paper and Code
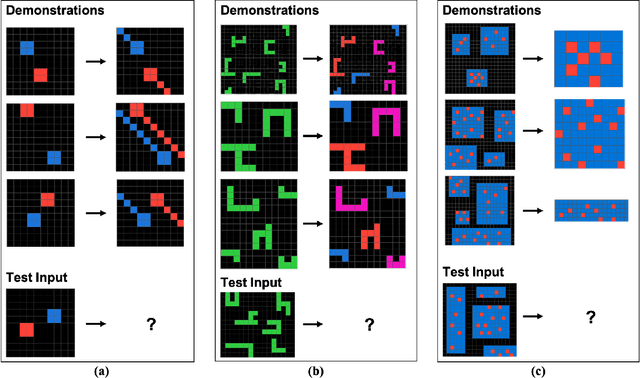
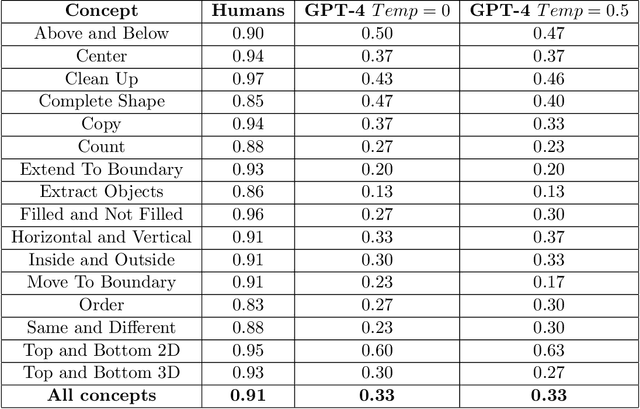

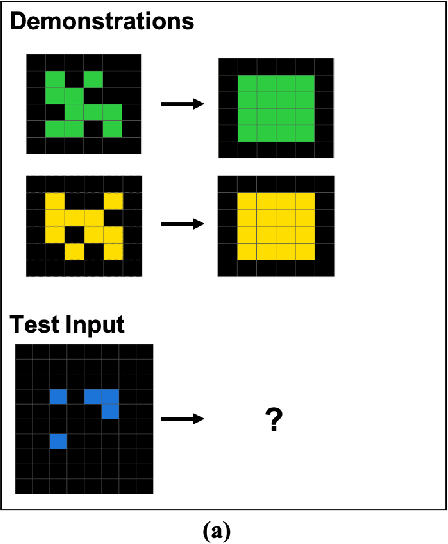
We explore the abstract reasoning abilities of text-only and multimodal versions of GPT-4, using the ConceptARC benchmark [10], which is designed to evaluate robust understanding and reasoning with core-knowledge concepts. We extend the work of Moskvichev et al. [10] by evaluating GPT-4 on more detailed, one-shot prompting (rather than simple, zero-shot prompts) with text versions of ConceptARC tasks, and by evaluating GPT-4V, the multimodal version of GPT-4, on zero- and one-shot prompts using image versions of the simplest tasks. Our experimental results support the conclusion that neither version of GPT-4 has developed robust abstraction abilities at humanlike levels.
* Corrected typo in email addresses
View paper on