 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetaExplainer: A Probabilistic Method to Explain Graph Neural Networks
Dec 16, 2024Graph neural networks (GNNs) are powerful tools for conducting inference on graph data but are often seen as "black boxes" due to difficulty in extracting meaningful subnetworks driving predictive performance. Many interpretable GNN methods exist, but they cannot quantify uncertainty in edge weights and suffer in predictive accuracy when applied to challenging graph structures. In this work, we proposed BetaExplainer which addresses these issues by using a sparsity-inducing prior to mask unimportant edges during model training. To evaluate our approach, we examine various simulated data sets with diverse real-world characteristics. Not only does this implementation provide a notion of edge importance uncertainty, it also improves upon evaluation metrics for challenging datasets compared to state-of-the art explainer methods.
Should I Stop or Should I Go: Early Stopping with Heterogeneous Populations
Jun 26, 2023Randomized experiments often need to be stopped prematurely due to the treatment having an unintended harmful effect. Existing methods that determine when to stop an experiment early are typically applied to the data in aggregate and do not account for treatment effect heterogeneity. In this paper, we study the early stopping of experiments for harm on heterogeneous populations. We first establish that current methods often fail to stop experiments when the treatment harms a minority group of participants. We then use causal machine learning to develop CLASH, the first broadly-applicable method for heterogeneous early stopping. We demonstrate CLASH's performance on simulated and real data and show that it yields effective early stopping for both clinical trials and A/B tests.
Generalizing Variational Autoencoders with Hierarchical Empirical Bayes
Jul 20, 2020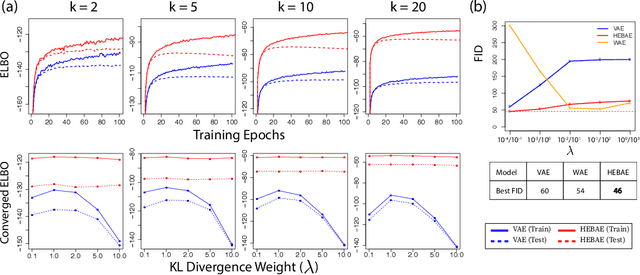



Variational Autoencoders (VAEs) have experienced recent success as data-generating models by using simple architectures that do not require significant fine-tuning of hyperparameters. However, VAEs are known to suffer from over-regularization which can lead to failure to escape local maxima. This phenomenon, known as posterior collapse, prevents learning a meaningful latent encoding of the data. Recent methods have mitigated this issue by deterministically moment-matching an aggregated posterior distribution to an aggregate prior. However, abandoning a probabilistic framework (and thus relying on point estimates) can both lead to a discontinuous latent space and generate unrealistic samples. Here we present Hierarchical Empirical Bayes Autoencoder (HEBAE), a computationally stable framework for probabilistic generative models. Our key contributions are two-fold. First, we make gains by placing a hierarchical prior over the encoding distribution, enabling us to adaptively balance the trade-off between minimizing the reconstruction loss function and avoiding over-regularization. Second, we show that assuming a general dependency structure between variables in the latent space produces better convergence onto the mean-field assumption for improved posterior inference. Overall, HEBAE is more robust to a wide-range of hyperparameter initializations than an analogous VAE. Using data from MNIST and CelebA, we illustrate the ability of HEBAE to generate higher quality samples based on FID score than existing autoencoder-based approaches.
Interpreting Deep Neural Networks Through Variable Importance
Jan 28, 2019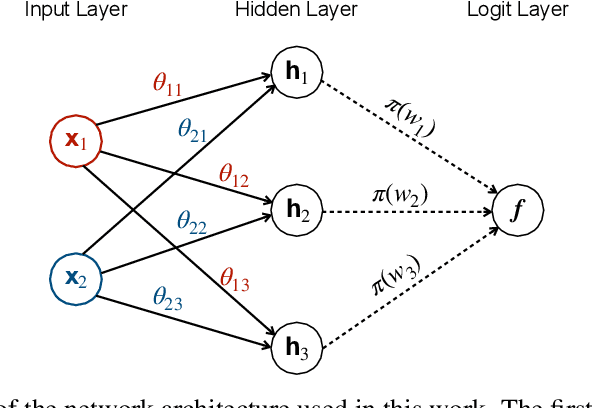

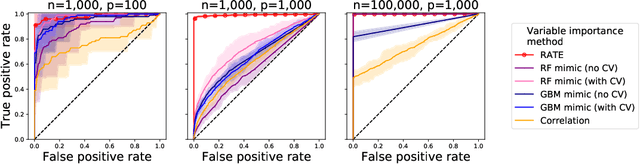
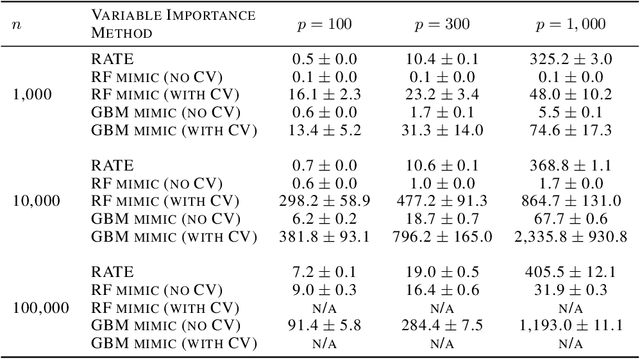
While the success of deep neural networks (DNNs) is well-established across a variety of domains, our ability to explain and interpret these methods is limited. Unlike previously proposed local methods which try to explain particular classification decisions, we focus on global interpretability and ask a universally applicable question: given a trained model, which features are the most important? In the context of neural networks, a feature is rarely important on its own, so our strategy is specifically designed to leverage partial covariance structures and incorporate variable dependence into feature ranking. Our methodological contributions in this paper are two-fold. First, we propose an effect size analogue for DNNs that is appropriate for applications with highly collinear predictors (ubiquitous in computer vision). Second, we extend the recently proposed "RelATive cEntrality" (RATE) measure (Crawford et al., 2019) to the Bayesian deep learning setting. RATE applies an information theoretic criterion to the posterior distribution of effect sizes to assess feature significance. We apply our framework to three broad application areas: computer vision, natural language processing, and social science.
Variable Prioritization in Nonlinear Black Box Methods: A Genetic Association Case Study
Aug 27, 2018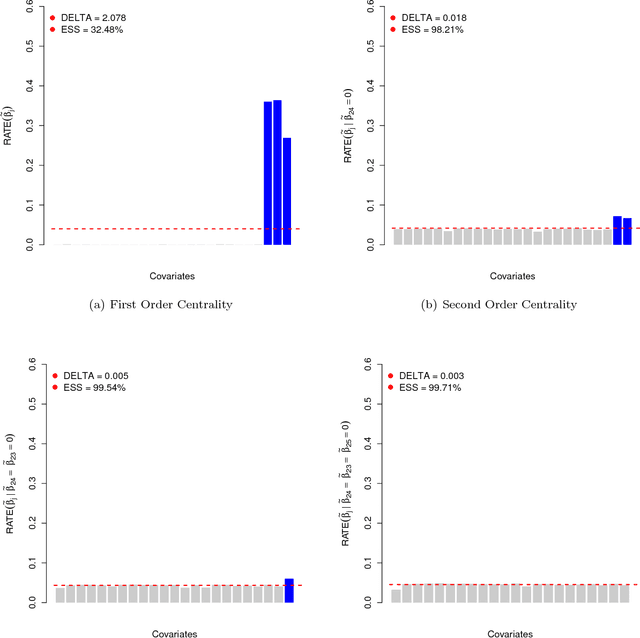

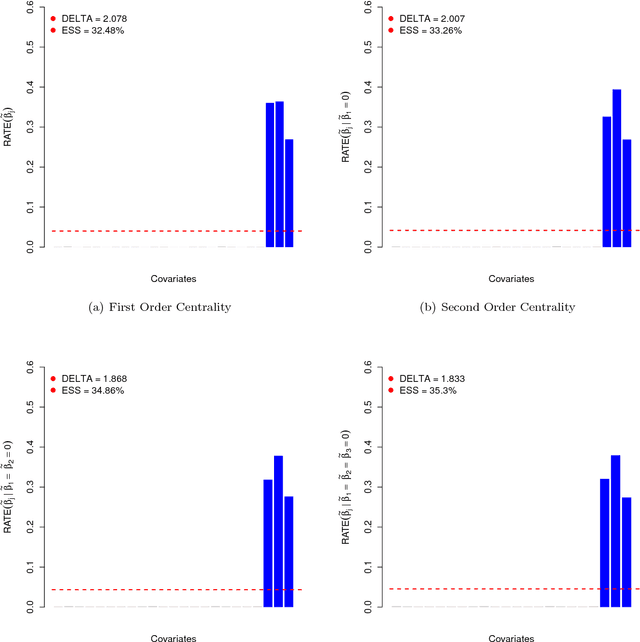

The central aim in this paper is to address variable selection questions in nonlinear and nonparametric regression. Motivated by statistical genetics, where nonlinear interactions are of particular interest, we introduce a novel and interpretable way to summarize the relative importance of predictor variables. Methodologically, we develop the "RelATive cEntrality" (RATE) measure to prioritize candidate genetic variants that are not just marginally important, but whose associations also stem from significant covarying relationships with other variants in the data. We illustrate RATE through Bayesian Gaussian process regression, but the methodological innovations apply to other "black box" methods. It is known that nonlinear models often exhibit greater predictive accuracy than linear models, particularly for phenotypes generated by complex genetic architectures. With detailed simulations and two real data association mapping studies, we show that applying RATE enables an explanation for this improved performance.
Bayesian Approximate Kernel Regression with Variable Selection
Jun 10, 2017
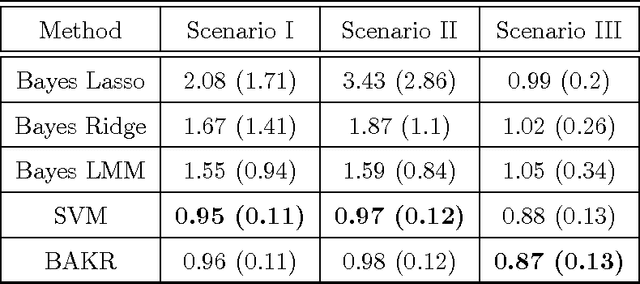
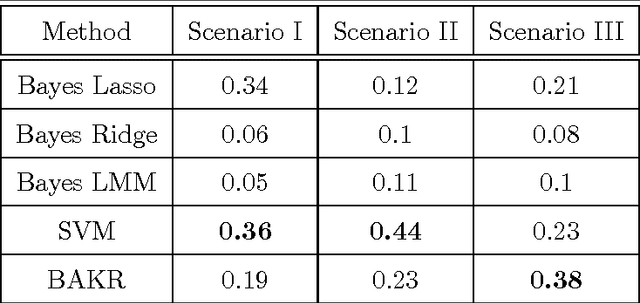

Nonlinear kernel regression models are often used in statistics and machine learning because they are more accurate than linear models. Variable selection for kernel regression models is a challenge partly because, unlike the linear regression setting, there is no clear concept of an effect size for regression coefficients. In this paper, we propose a novel framework that provides an effect size analog of each explanatory variable for Bayesian kernel regression models when the kernel is shift-invariant --- for example, the Gaussian kernel. We use function analytic properties of shift-invariant reproducing kernel Hilbert spaces (RKHS) to define a linear vector space that: (i) captures nonlinear structure, and (ii) can be projected onto the original explanatory variables. The projection onto the original explanatory variables serves as an analog of effect sizes. The specific function analytic property we use is that shift-invariant kernel functions can be approximated via random Fourier bases. Based on the random Fourier expansion we propose a computationally efficient class of Bayesian approximate kernel regression (BAKR) models for both nonlinear regression and binary classification for which one can compute an analog of effect sizes. We illustrate the utility of BAKR by examining two important problems in statistical genetics: genomic selection (i.e. phenotypic prediction) and association mapping (i.e. inference of significant variants or loci). State-of-the-art methods for genomic selection and association mapping are based on kernel regression and linear models, respectively. BAKR is the first method that is competitive in both settings.