 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Arrival Times with Recurrent Neural Networks for Personalized Demand Forecasting
Dec 29, 2018

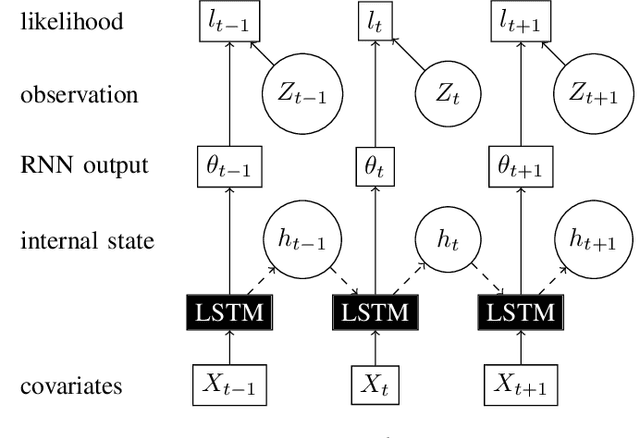
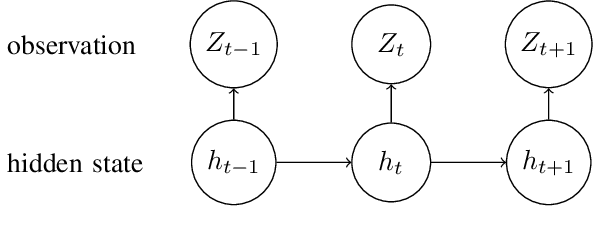
Access to a large variety of data across a massive population has made it possible to predict customer purchase patterns and responses to marketing campaigns. In particular, accurate demand forecasts for popular products with frequent repeat purchases are essential since these products are one of the main drivers of profits. However, buyer purchase patterns are extremely diverse and sparse on a per-product level due to population heterogeneity as well as dependence in purchase patterns across product categories. Traditional methods in survival analysis have proven effective in dealing with censored data by assuming parametric distributions on inter-arrival times. Distributional parameters are then fitted, typically in a regression framework. On the other hand, neural-network based models take a non-parametric approach to learn relations from a larger functional class. However, the lack of distributional assumptions make it difficult to model partially observed data. In this paper, we model directly the inter-arrival times as well as the partially observed information at each time step in a survival-based approach using Recurrent Neural Networks (RNN) to model purchase times jointly over several products. Instead of predicting a point estimate for inter-arrival times, the RNN outputs parameters that define a distributional estimate. The loss function is the negative log-likelihood of these parameters given partially observed data. This approach allows one to leverage both fully observed data as well as partial information. By externalizing the censoring problem through a log-likelihood loss function, we show that substantial improvements over state-of-the-art machine learning methods can be achieved. We present experimental results based on two open datasets as well as a study on a real dataset from a large retailer.
Merge Non-Dominated Sorting Algorithm for Many-Objective Optimization
Sep 17, 2018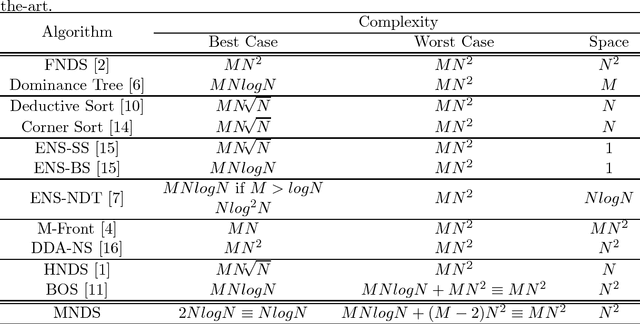
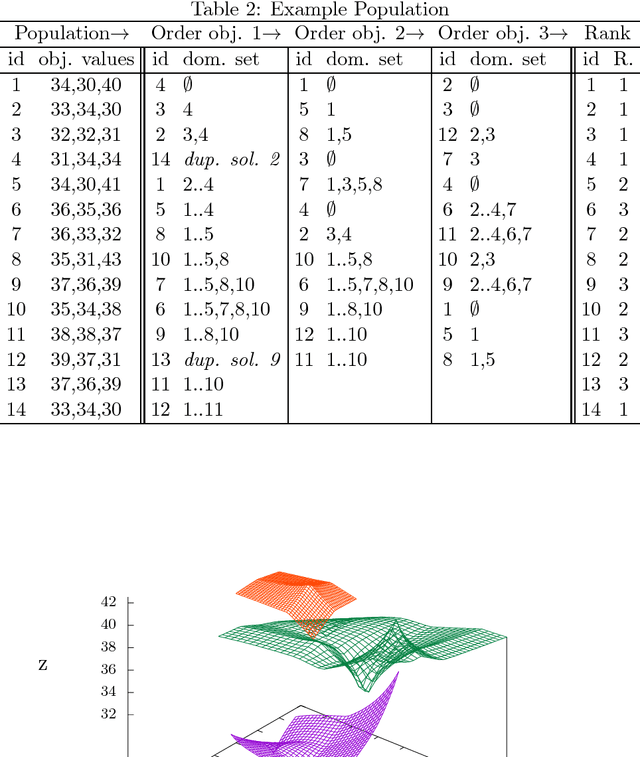
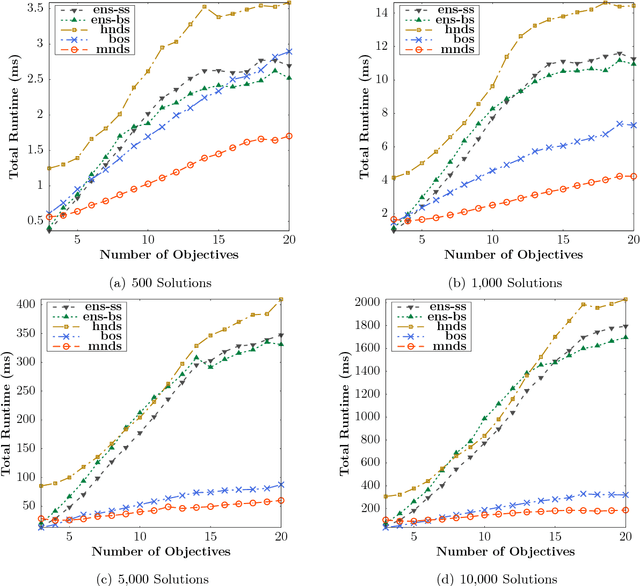
Many Pareto-based multi-objective evolutionary algorithms require to rank the solutions of the population in each iteration according to the dominance principle, what can become a costly operation particularly in the case of dealing with many-objective optimization problems. In this paper, we present a new efficient algorithm for computing the non-dominated sorting procedure, called Merge Non-Dominated Sorting (MNDS), which has a best computational complexity of $\Theta(NlogN)$ and a worst computational complexity of $\Theta(MN^2)$. Our approach is based on the computation of the dominance set of each solution by taking advantage of the characteristics of the merge sort algorithm. We compare the MNDS against four well-known techniques that can be considered as the state-of-the-art. The results indicate that the MNDS algorithm outperforms the other techniques in terms of number of comparisons as well as the total running time.