 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LSTM-based Test Selection Method for Self-Driving Cars
Jan 07, 2025

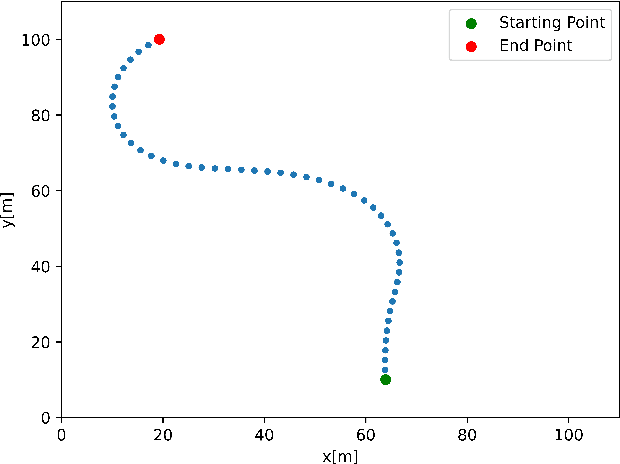
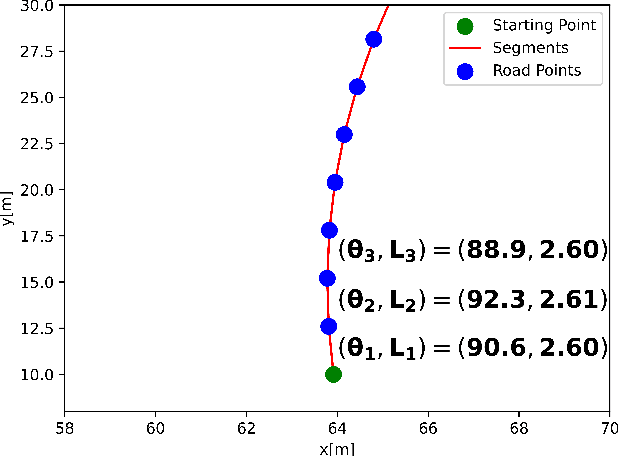
Self-driving cars require extensive testing, which can be costly in terms of time. To optimize this process, simple and straightforward tests should be excluded, focusing on challenging tests instead. This study addresses the test selection problem for lane-keeping systems for self-driving cars. Road segment features, such as angles and lengths, were extracted and treated as sequences, enabling classification of the test cases as "safe" or "unsafe" using a long short-term memory (LSTM) model. The proposed model is compared against machine learning-based test selectors. Results demonstrated that the LSTM-based method outperformed machine learning-based methods in accuracy and precision metrics while exhibiting comparable performance in recall and F1 scores. This work introduces a novel deep learning-based approach to the road classification problem, providing an effective solution for self-driving car test selection using a simulation environment.
Software defect prediction with zero-inflated Poisson models
Oct 30, 2019
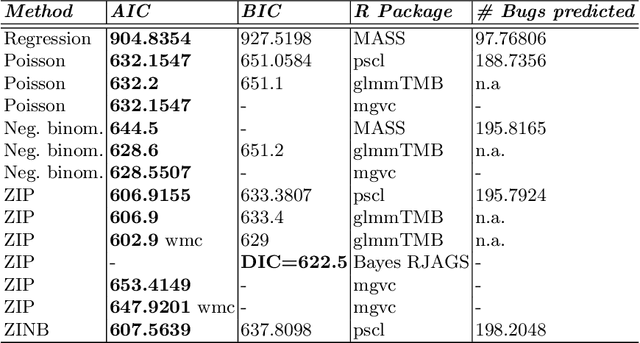
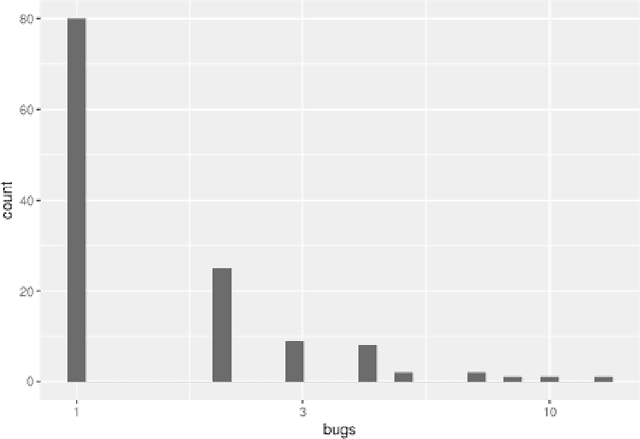
In this work we apply several Poisson and zero-inflated models for software defect prediction. We apply different functions from several R packages such as pscl, MASS, R2Jags and the recent glmmTMB. We test the functions using the Equinox dataset. The results show that Zero-inflated models, fitted with either maximum likelihood estimation or with Bayesian approach, are slightly better than other models, using the AIC as selection criterion.
The Impact of Annotation Guidelines and Annotated Data on Extracting App Features from App Reviews
Oct 11, 2018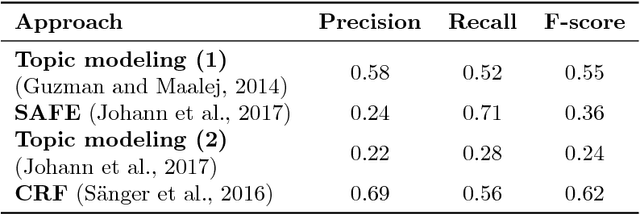
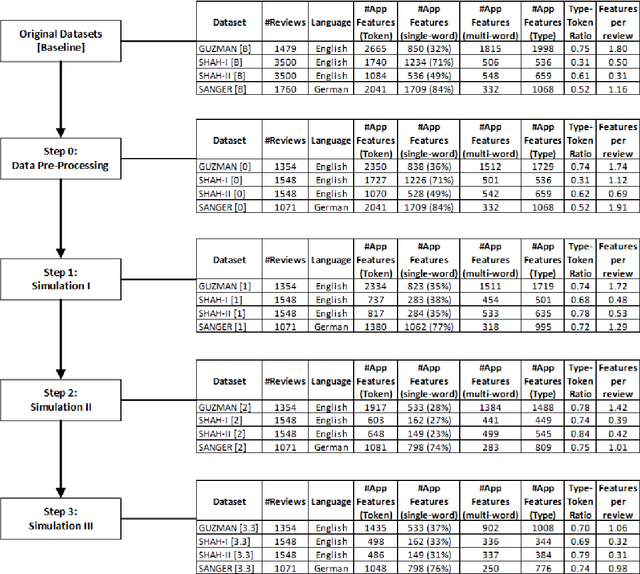

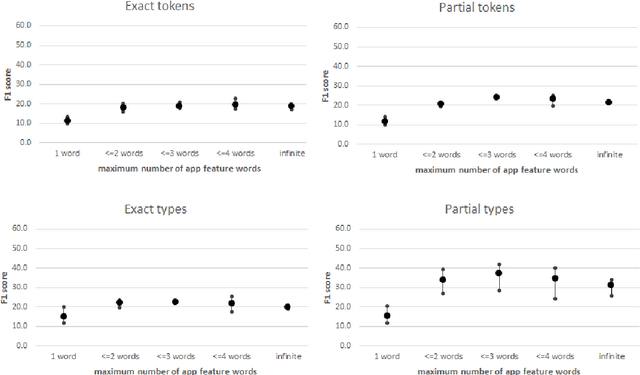
Annotation guidelines used to guide the annotation of training and evaluation datasets can have a considerable impact on the quality of machine learning models. In this study, we explore the effects of annotation guidelines on the quality of app feature extraction models. As a main result, we propose several changes to the existing annotation guidelines with a goal of making the extracted app features more useful and informative to the app developers. We test the proposed changes via simulating the application of the new annotation guidelines and then evaluating the performance of the supervised machine learning models trained on datasets annotated with initial and simulated guidelines. While the overall performance of automatic app feature extraction remains the same as compared to the model trained on the dataset with initial annotations, the features extracted by the model trained on the dataset with simulated new annotations are less noisy and more informative to the app developers. Secondly, we are interested in what kind of annotated training data is necessary for training an automatic app feature extraction model. In particular, we explore whether the training set should contain annotated app reviews from those apps/app categories on which the model is subsequently planned to be applied, or is it sufficient to have annotated app reviews from any app available for training, even when these apps are from very different categories compared to the test app. Our experiments show that having annotated training reviews from the test app is not necessary although including them into training set helps to improve recall. Furthermore, we test whether augmenting the training set with annotated product reviews helps to improve the performance of app feature extraction. We find that the models trained on augmented training set lead to improved recall but at the cost of the drop in precision.