 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe challenge of generating and evolving real-life like synthetic test data without accessing real-world raw data -- a Systematic Review
Feb 06, 2026Background: High-level system testing of applications that use data from e-Government services as input requires test data that is real-life-like but where the privacy of personal information is guaranteed. Applications with such strong requirement include information exchange between countries, medicine, banking, etc. This review aims to synthesize the current state-of-the-practice in this domain. Objectives: The objective of this Systematic Review is to identify existing approaches for creating and evolving synthetic test data without using real-life raw data. Methods: We followed well-known methodologies for conducting systematic literature reviews, including the ones from Kitchenham as well as guidelines for analysing the limitations of our review and its threats to validity. Results: A variety of methods and tools exist for creating privacy-preserving test data. Our search found 1,013 publications in IEEE Xplore, ACM Digital Library, and SCOPUS. We extracted data from 75 of those publications and identified 37 approaches that answer our research question partly. A common prerequisite for using these methods and tools is direct access to real-life data for data anonymization or synthetic test data generation. Nine existing synthetic test data generation approaches were identified that were closest to answering our research question. Nevertheless, further work would be needed to add the ability to evolve synthetic test data to the existing approaches. Conclusions: None of the publications really covered our requirements completely, only partially. Synthetic test data evolution is a field that has not received much attention from researchers but needs to be explored in Digital Government Solutions, especially since new legal regulations are being placed in force in many countries.
* 22 pages
An LSTM-based Test Selection Method for Self-Driving Cars
Jan 07, 2025

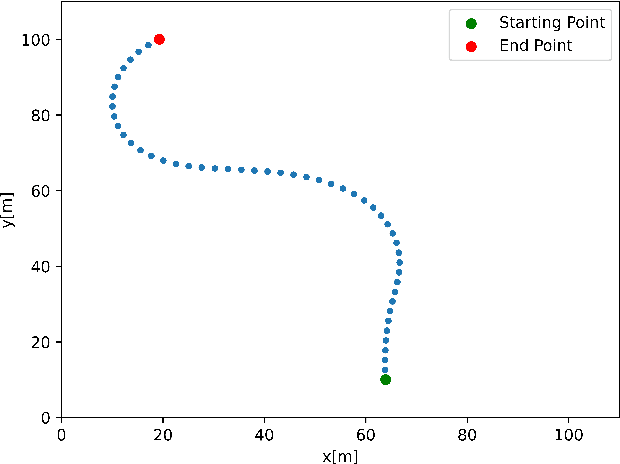
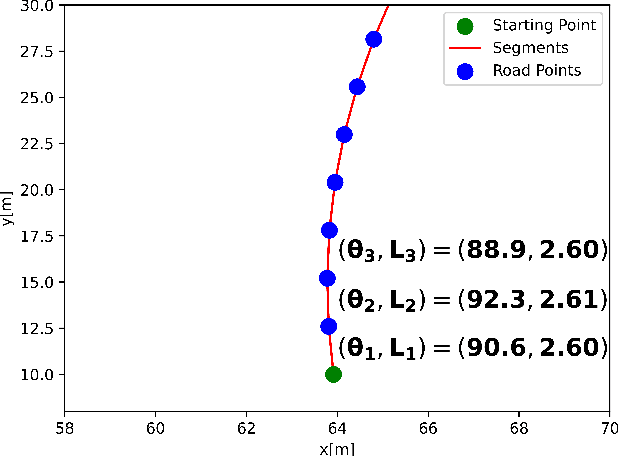
Self-driving cars require extensive testing, which can be costly in terms of time. To optimize this process, simple and straightforward tests should be excluded, focusing on challenging tests instead. This study addresses the test selection problem for lane-keeping systems for self-driving cars. Road segment features, such as angles and lengths, were extracted and treated as sequences, enabling classification of the test cases as "safe" or "unsafe" using a long short-term memory (LSTM) model. The proposed model is compared against machine learning-based test selectors. Results demonstrated that the LSTM-based method outperformed machine learning-based methods in accuracy and precision metrics while exhibiting comparable performance in recall and F1 scores. This work introduces a novel deep learning-based approach to the road classification problem, providing an effective solution for self-driving car test selection using a simulation environment.
A Fine-grained Sentiment Analysis of App Reviews using Large Language Models: An Evaluation Study
Sep 11, 2024



Analyzing user reviews for sentiment towards app features can provide valuable insights into users' perceptions of app functionality and their evolving needs. Given the volume of user reviews received daily, an automated mechanism to generate feature-level sentiment summaries of user reviews is needed. Recent advances in Large Language Models (LLMs) such as ChatGPT have shown impressive performance on several new tasks without updating the model's parameters i.e. using zero or a few labeled examples. Despite these advancements, LLMs' capabilities to perform feature-specific sentiment analysis of user reviews remain unexplored. This study compares the performance of state-of-the-art LLMs, including GPT-4, ChatGPT, and LLama-2-chat variants, for extracting app features and associated sentiments under 0-shot, 1-shot, and 5-shot scenarios. Results indicate the best-performing GPT-4 model outperforms rule-based approaches by 23.6% in f1-score with zero-shot feature extraction; 5-shot further improving it by 6%. GPT-4 achieves a 74% f1-score for predicting positive sentiment towards correctly predicted app features, with 5-shot enhancing it by 7%. Our study suggests that LLM models are promising for generating feature-specific sentiment summaries of user reviews.
The Impact of Annotation Guidelines and Annotated Data on Extracting App Features from App Reviews
Oct 11, 2018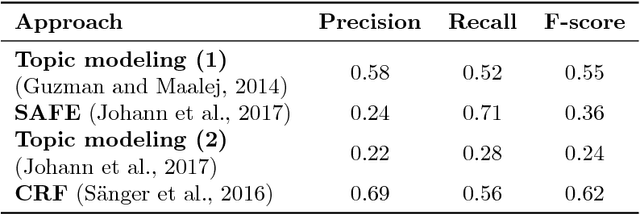
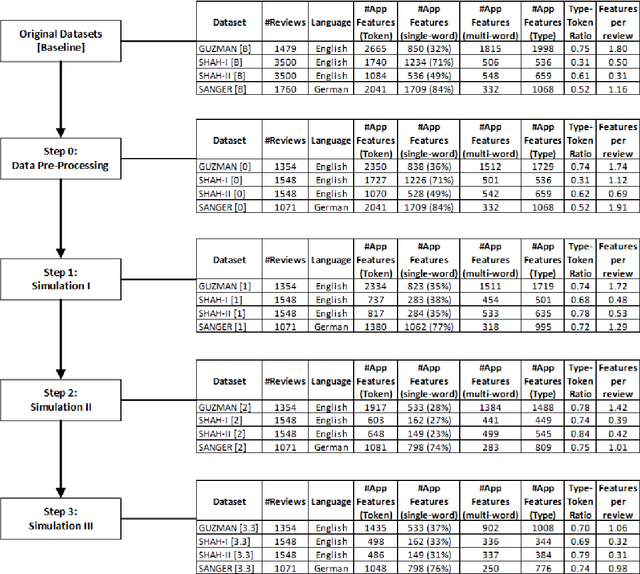

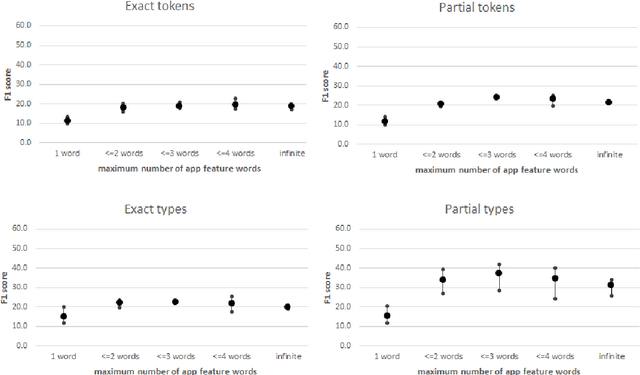
Annotation guidelines used to guide the annotation of training and evaluation datasets can have a considerable impact on the quality of machine learning models. In this study, we explore the effects of annotation guidelines on the quality of app feature extraction models. As a main result, we propose several changes to the existing annotation guidelines with a goal of making the extracted app features more useful and informative to the app developers. We test the proposed changes via simulating the application of the new annotation guidelines and then evaluating the performance of the supervised machine learning models trained on datasets annotated with initial and simulated guidelines. While the overall performance of automatic app feature extraction remains the same as compared to the model trained on the dataset with initial annotations, the features extracted by the model trained on the dataset with simulated new annotations are less noisy and more informative to the app developers. Secondly, we are interested in what kind of annotated training data is necessary for training an automatic app feature extraction model. In particular, we explore whether the training set should contain annotated app reviews from those apps/app categories on which the model is subsequently planned to be applied, or is it sufficient to have annotated app reviews from any app available for training, even when these apps are from very different categories compared to the test app. Our experiments show that having annotated training reviews from the test app is not necessary although including them into training set helps to improve recall. Furthermore, we test whether augmenting the training set with annotated product reviews helps to improve the performance of app feature extraction. We find that the models trained on augmented training set lead to improved recall but at the cost of the drop in precision.