 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Emotion Recognition with Dual-Sequence LSTM Architecture
Paper and Code
Oct 20, 2019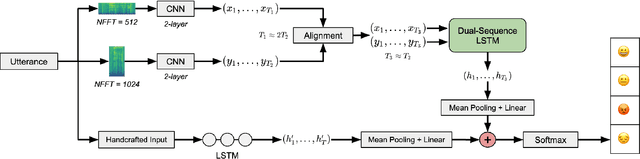
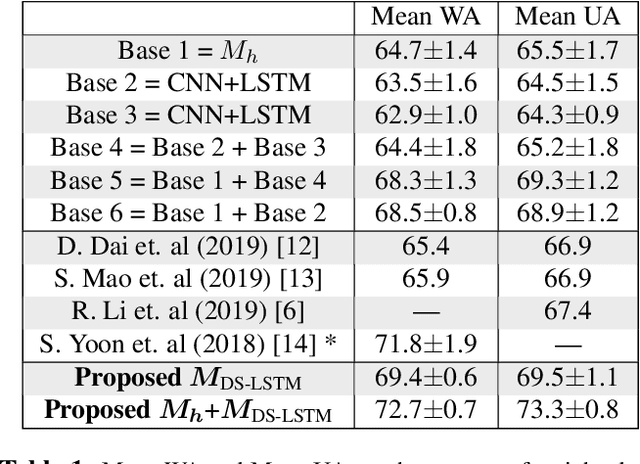
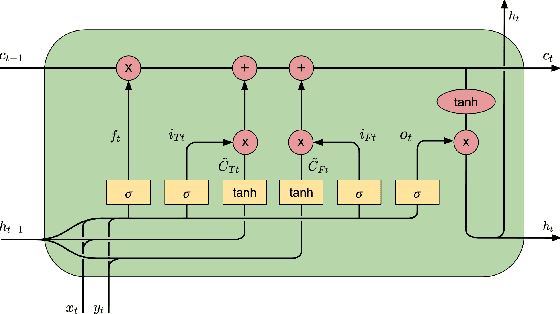
Speech Emotion Recognition (SER) has emerged as a critical component of the next generation of human-machine interfacing technologies. In this work, we propose a new dual-level model that combines handcrafted and raw features for audio signals. Each utterance is preprocessed into a handcrafted input and two mel-spectrograms at different time-frequency resolutions. An LSTM processes the handcrafted input, while a novel LSTM architecture, denoted as Dual-Sequence LSTM (DS-LSTM), processes the two mel-spectrograms simultaneously. The outputs are later averaged to produce a final classification of the utterance. Our proposed model achieves, on average, a weighted accuracy of 72.7% and an unweighted accuracy of 73.3% --- a 6% improvement over current state-of-the-art models --- and is comparable with multimodal SER models that leverage textual information.