 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Classification: Modulating Domain-Specific Knowledge for Multidomain Crowd Counting
Feb 06, 2024



Multidomain crowd counting aims to learn a general model for multiple diverse datasets. However, deep networks prefer modeling distributions of the dominant domains instead of all domains, which is known as domain bias. In this study, we propose a simple-yet-effective Modulating Domain-specific Knowledge Network (MDKNet) to handle the domain bias issue in multidomain crowd counting. MDKNet is achieved by employing the idea of `modulating', enabling deep network balancing and modeling different distributions of diverse datasets with little bias. Specifically, we propose an Instance-specific Batch Normalization (IsBN) module, which serves as a base modulator to refine the information flow to be adaptive to domain distributions. To precisely modulating the domain-specific information, the Domain-guided Virtual Classifier (DVC) is then introduced to learn a domain-separable latent space. This space is employed as an input guidance for the IsBN modulator, such that the mixture distributions of multiple datasets can be well treated. Extensive experiments performed on popular benchmarks, including Shanghai-tech A/B, QNRF and NWPU, validate the superiority of MDKNet in tackling multidomain crowd counting and the effectiveness for multidomain learning. Code is available at \url{https://github.com/csguomy/MDKNet}.
* Multidomain learning; Domain-guided virtual classifier; Instance-specific batch normalization
Regressor-Segmenter Mutual Prompt Learning for Crowd Counting
Dec 04, 2023Crowd counting has achieved significant progress by training regressors to predict instance positions. In heavily crowded scenarios, however, regressors are challenged by uncontrollable annotation variance, which causes density map bias and context information inaccuracy. In this study, we propose mutual prompt learning (mPrompt), which leverages a regressor and a segmenter as guidance for each other, solving bias and inaccuracy caused by annotation variance while distinguishing foreground from background. In specific, mPrompt leverages point annotations to tune the segmenter and predict pseudo head masks in a way of point prompt learning. It then uses the predicted segmentation masks, which serve as spatial constraint, to rectify biased point annotations as context prompt learning. mPrompt defines a way of mutual information maximization from prompt learning, mitigating the impact of annotation variance while improving model accuracy. Experiments show that mPrompt significantly reduces the Mean Average Error (MAE), demonstrating the potential to be general framework for down-stream vision tasks.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021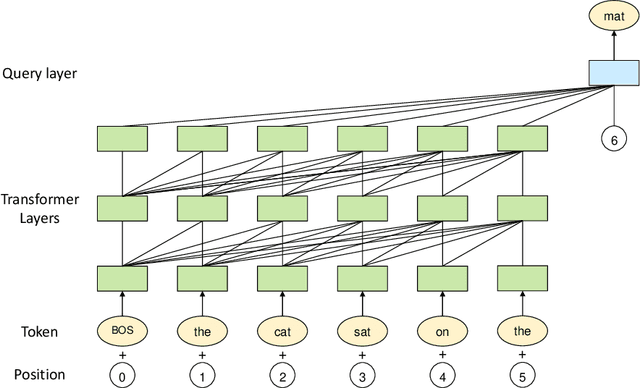
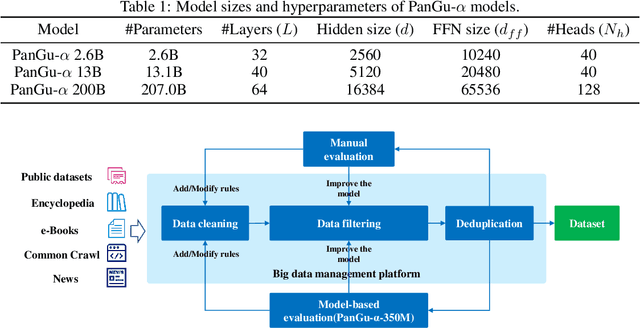
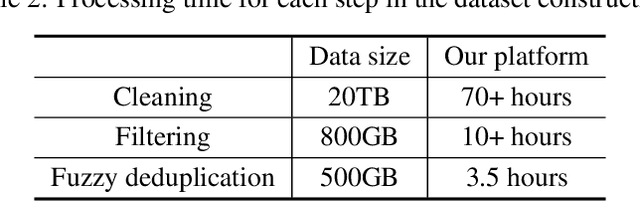
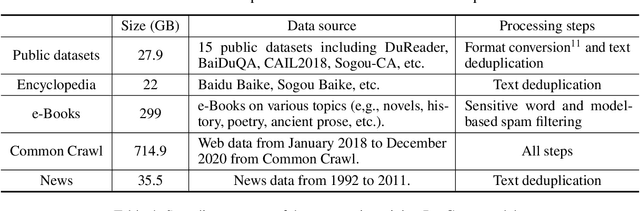
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.