 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog Neural Controlled Differential Equations: The Lie Brackets Make a Difference
Feb 28, 2024The vector field of a controlled differential equation (CDE) describes the relationship between a control path and the evolution of a solution path. Neural CDEs (NCDEs) treat time series data as observations from a control path, parameterise a CDE's vector field using a neural network, and use the solution path as a continuously evolving hidden state. As their formulation makes them robust to irregular sampling rates, NCDEs are a powerful approach for modelling real-world data. Building on neural rough differential equations (NRDEs), we introduce Log-NCDEs, a novel and effective method for training NCDEs. The core component of Log-NCDEs is the Log-ODE method, a tool from the study of rough paths for approximating a CDE's solution. On a range of multivariate time series classification benchmarks, Log-NCDEs are shown to achieve a higher average test set accuracy than NCDEs, NRDEs, and two state-of-the-art models, S5 and the linear recurrent unit.
Signature Methods in Machine Learning
Jun 29, 2022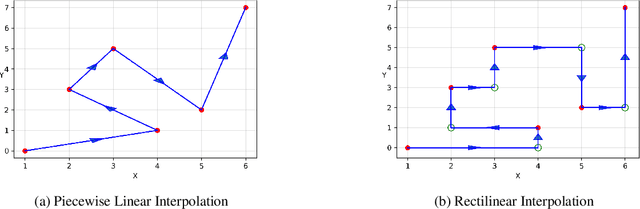
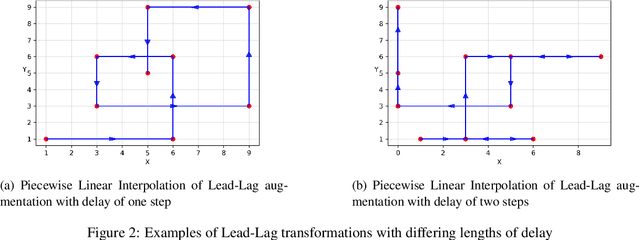
Signature-based techniques give mathematical insight into the interactions between complex streams of evolving data. These insights can be quite naturally translated into numerical approaches to understanding streamed data, and perhaps because of their mathematical precision, have proved useful in analysing streamed data in situations where the data is irregular, and not stationary, and the dimension of the data and the sample sizes are both moderate. Understanding streamed multi-modal data is exponential: a word in $n$ letters from an alphabet of size $d$ can be any one of $d^n$ messages. Signatures remove the exponential amount of noise that arises from sampling irregularity, but an exponential amount of information still remain. This survey aims to stay in the domain where that exponential scaling can be managed directly. Scalability issues are an important challenge in many problems but would require another survey article and further ideas. This survey describes a range of contexts where the data sets are small enough to remove the possibility of massive machine learning, and the existence of small sets of context free and principled features can be used effectively. The mathematical nature of the tools can make their use intimidating to non-mathematicians. The examples presented in this article are intended to bridge this communication gap and provide tractable working examples drawn from the machine learning context. Notebooks are available online for several of these examples. This survey builds on the earlier paper of Ilya Chevryev and Andrey Kormilitzin which had broadly similar aims at an earlier point in the development of this machinery. This article illustrates how the theoretical insights offered by signatures are simply realised in the analysis of application data in a way that is largely agnostic to the data type.