 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignature Methods in Machine Learning
Paper and Code
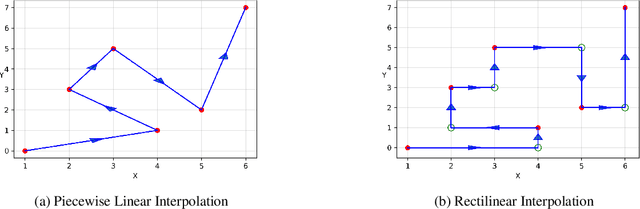
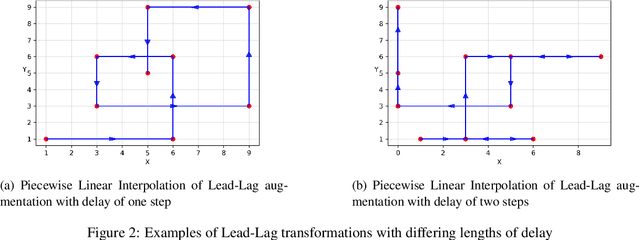
Signature-based techniques give mathematical insight into the interactions between complex streams of evolving data. These insights can be quite naturally translated into numerical approaches to understanding streamed data, and perhaps because of their mathematical precision, have proved useful in analysing streamed data in situations where the data is irregular, and not stationary, and the dimension of the data and the sample sizes are both moderate. Understanding streamed multi-modal data is exponential: a word in $n$ letters from an alphabet of size $d$ can be any one of $d^n$ messages. Signatures remove the exponential amount of noise that arises from sampling irregularity, but an exponential amount of information still remain. This survey aims to stay in the domain where that exponential scaling can be managed directly. Scalability issues are an important challenge in many problems but would require another survey article and further ideas. This survey describes a range of contexts where the data sets are small enough to remove the possibility of massive machine learning, and the existence of small sets of context free and principled features can be used effectively. The mathematical nature of the tools can make their use intimidating to non-mathematicians. The examples presented in this article are intended to bridge this communication gap and provide tractable working examples drawn from the machine learning context. Notebooks are available online for several of these examples. This survey builds on the earlier paper of Ilya Chevryev and Andrey Kormilitzin which had broadly similar aims at an earlier point in the development of this machinery. This article illustrates how the theoretical insights offered by signatures are simply realised in the analysis of application data in a way that is largely agnostic to the data type.