 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAS: A Simple, Accurate and Scalable Node Classification Algorithm
Apr 19, 2021
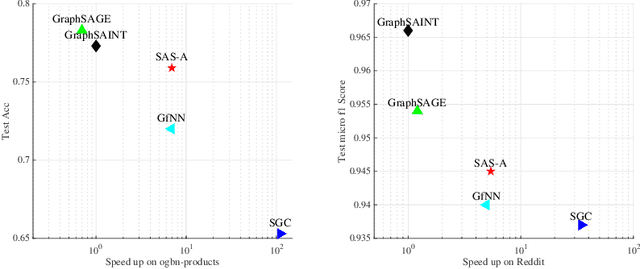
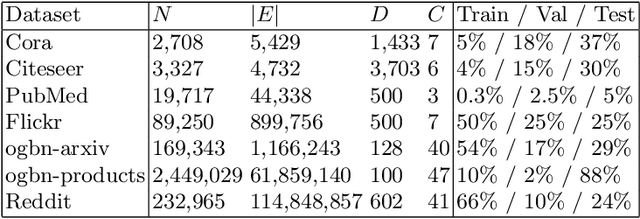
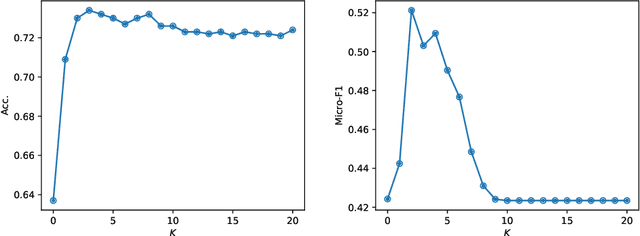
Graph neural networks have achieved state-of-the-art accuracy for graph node classification. However, GNNs are difficult to scale to large graphs, for example frequently encountering out-of-memory errors on even moderate size graphs. Recent works have sought to address this problem using a two-stage approach, which first aggregates data along graph edges, then trains a classifier without using additional graph information. These methods can run on much larger graphs and are orders of magnitude faster than GNNs, but achieve lower classification accuracy. We propose a novel two-stage algorithm based on a simple but effective observation: we should first train a classifier then aggregate, rather than the other way around. We show our algorithm is faster and can handle larger graphs than existing two-stage algorithms, while achieving comparable or higher accuracy than popular GNNs. We also present a theoretical basis to explain our algorithm's improved accuracy, by giving a synthetic nonlinear dataset in which performing aggregation before classification actually decreases accuracy compared to doing classification alone, while our classify then aggregate approach substantially improves accuracy compared to classification alone.