 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Mamba: Long-Context Speech Recognition with Selective State Spaces Models
Paper and Code
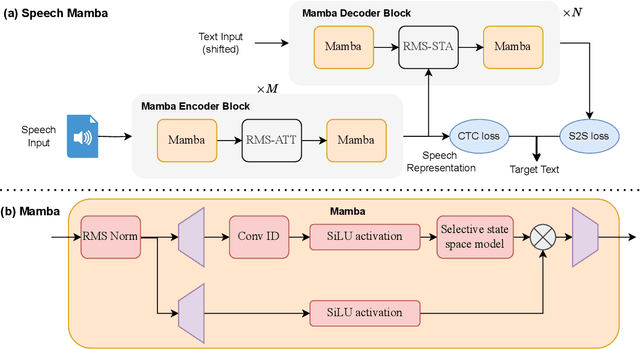


Current automatic speech recognition systems struggle with modeling long speech sequences due to high quadratic complexity of Transformer-based models. Selective state space models such as Mamba has performed well on long-sequence modeling in natural language processing and computer vision tasks. However, research endeavors in speech technology tasks has been under-explored. We propose Speech-Mamba, which incorporates selective state space modeling in Transformer neural architectures. Long sequence representations with selective state space models in Speech-Mamba is complemented with lower-level representations from Transformer-based modeling. Speech-mamba achieves better capacity to model long-range dependencies, as it scales near-linearly with sequence length.