 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmo-DPO: Controllable Emotional Speech Synthesis through Direct Preference Optimization
Paper and Code
Sep 16, 2024
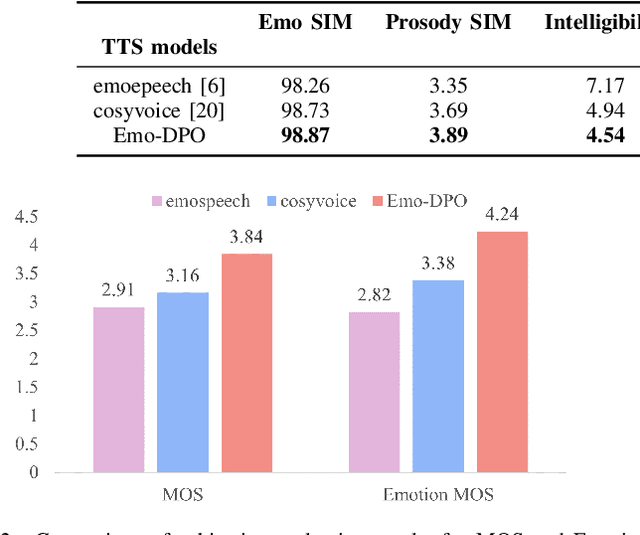


Current emotional text-to-speech (TTS) models predominantly conduct supervised training to learn the conversion from text and desired emotion to its emotional speech, focusing on a single emotion per text-speech pair. These models only learn the correct emotional outputs without fully comprehending other emotion characteristics, which limits their capabilities of capturing the nuances between different emotions. We propose a controllable Emo-DPO approach, which employs direct preference optimization to differentiate subtle emotional nuances between emotions through optimizing towards preferred emotions over less preferred emotional ones. Instead of relying on traditional neural architectures used in existing emotional TTS models, we propose utilizing the emotion-aware LLM-TTS neural architecture to leverage LLMs' in-context learning and instruction-following capabilities. Comprehensive experiments confirm that our proposed method outperforms the existing baselines.