 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling and bias codes for modeling speaker-adaptive DNN-based speech synthesis systems
Paper and Code
Oct 01, 2018

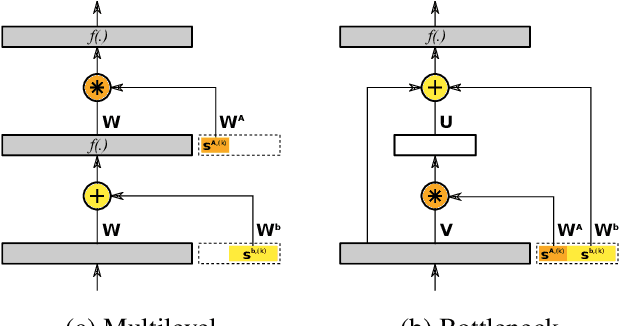

Most neural-network based speaker-adaptive acoustic models for speech synthesis can be categorized into either layer-based or input-code approaches. Although both approaches have their own pros and cons, most existing works on speaker adaptation focus on improving one or the other. In this paper, after we first systematically overview the common principles of neural-network based speaker-adaptive models, we show that these approaches can be represented in a unified framework and can be generalized further. More specifically, we introduce the use of scaling and bias codes as generalized means for speaker-adaptive transformation. By utilizing these codes, we can create a more efficient factorized speaker-adaptive model and capture advantages of both approaches while reducing their disadvantages. The experiments show that the proposed method can improve the performance of speaker adaptation compared with speaker adaptation based on the conventional input code.