 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Universal Adapter Learning with Knowledge Distillation for End-to-End Multilingual Speech Recognition
Paper and Code

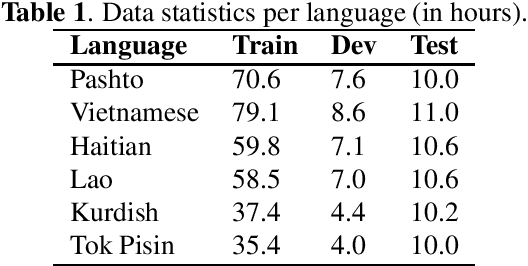
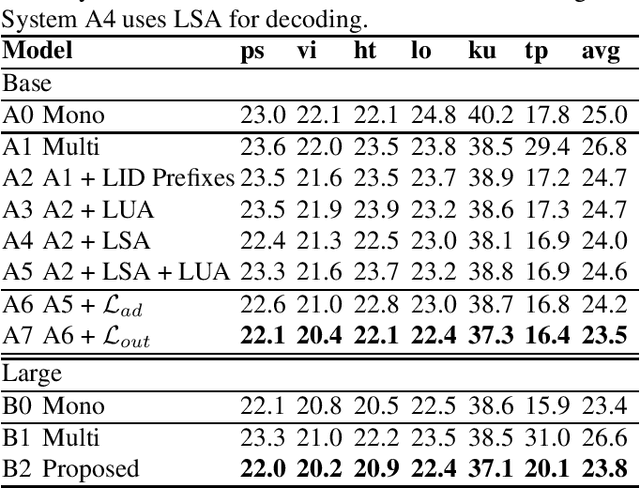

In this paper, we propose a language-universal adapter learning framework based on a pre-trained model for end-to-end multilingual automatic speech recognition (ASR). For acoustic modeling, the wav2vec 2.0 pre-trained model is fine-tuned by inserting language-specific and language-universal adapters. An online knowledge distillation is then used to enable the language-universal adapters to learn both language-specific and universal features. The linguistic information confusion is also reduced by leveraging language identifiers (LIDs). With LIDs we perform a position-wise modification on the multi-head attention outputs. In the inference procedure, the language-specific adapters are removed while the language-universal adapters are kept activated. The proposed method improves the recognition accuracy and addresses the linear increase of the number of adapters' parameters with the number of languages in common multilingual ASR systems. Experiments on the BABEL dataset confirm the effectiveness of the proposed framework. Compared to the conventional multilingual model, a 3.3% absolute error rate reduction is achieved. The code is available at: https://github.com/shen9712/UniversalAdapterLearning.