 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts
Feb 13, 2026We present Nanbeige4.1-3B, a unified generalist language model that simultaneously achieves strong agentic behavior, code generation, and general reasoning with only 3B parameters. To the best of our knowledge, it is the first open-source small language model (SLM) to achieve such versatility in a single model. To improve reasoning and preference alignment, we combine point-wise and pair-wise reward modeling, ensuring high-quality, human-aligned responses. For code generation, we design complexity-aware rewards in Reinforcement Learning, optimizing both correctness and efficiency. In deep search, we perform complex data synthesis and incorporate turn-level supervision during training. This enables stable long-horizon tool interactions, allowing Nanbeige4.1-3B to reliably execute up to 600 tool-call turns for complex problem-solving. Extensive experimental results show that Nanbeige4.1-3B significantly outperforms prior models of similar scale, such as Nanbeige4-3B-2511 and Qwen3-4B, even achieving superior performance compared to much larger models, such as Qwen3-30B-A3B. Our results demonstrate that small models can achieve both broad competence and strong specialization simultaneously, redefining the potential of 3B parameter models.
Circuit-Aware SAT Solving: Guiding CDCL via Conditional Probabilities
Aug 06, 2025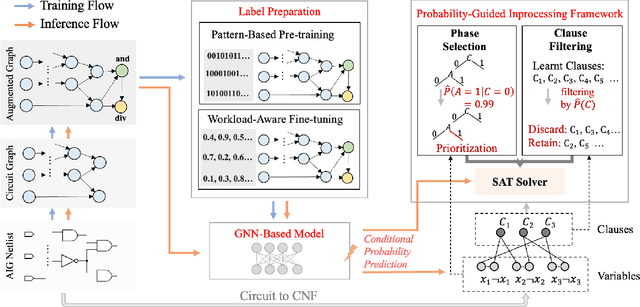

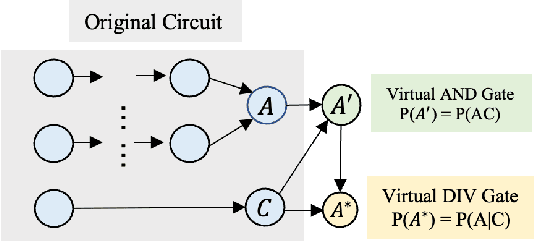

Circuit Satisfiability (CSAT) plays a pivotal role in Electronic Design Automation. The standard workflow for solving CSAT problems converts circuits into Conjunctive Normal Form (CNF) and employs generic SAT solvers powered by Conflict-Driven Clause Learning (CDCL). However, this process inherently discards rich structural and functional information, leading to suboptimal solver performance. To address this limitation, we introduce CASCAD, a novel circuit-aware SAT solving framework that directly leverages circuit-level conditional probabilities computed via Graph Neural Networks (GNNs). By explicitly modeling gate-level conditional probabilities, CASCAD dynamically guides two critical CDCL heuristics -- variable phase selection and clause managementto significantly enhance solver efficiency. Extensive evaluations on challenging real-world Logical Equivalence Checking (LEC) benchmarks demonstrate that CASCAD reduces solving times by up to 10x compared to state-of-the-art CNF-based approaches, achieving an additional 23.5% runtime reduction via our probability-guided clause filtering strategy. Our results underscore the importance of preserving circuit-level structural insights within SAT solvers, providing a robust foundation for future improvements in SAT-solving efficiency and EDA tool design.
Rethinking Circuit Completeness in Language Models: AND, OR, and ADDER Gates
May 15, 2025Circuit discovery has gradually become one of the prominent methods for mechanistic interpretability, and research on circuit completeness has also garnered increasing attention. Methods of circuit discovery that do not guarantee completeness not only result in circuits that are not fixed across different runs but also cause key mechanisms to be omitted. The nature of incompleteness arises from the presence of OR gates within the circuit, which are often only partially detected in standard circuit discovery methods. To this end, we systematically introduce three types of logic gates: AND, OR, and ADDER gates, and decompose the circuit into combinations of these logical gates. Through the concept of these gates, we derive the minimum requirements necessary to achieve faithfulness and completeness. Furthermore, we propose a framework that combines noising-based and denoising-based interventions, which can be easily integrated into existing circuit discovery methods without significantly increasing computational complexity. This framework is capable of fully identifying the logic gates and distinguishing them within the circuit. In addition to the extensive experimental validation of the framework's ability to restore the faithfulness, completeness, and sparsity of circuits, using this framework, we uncover fundamental properties of the three logic gates, such as their proportions and contributions to the output, and explore how they behave among the functionalities of language models.
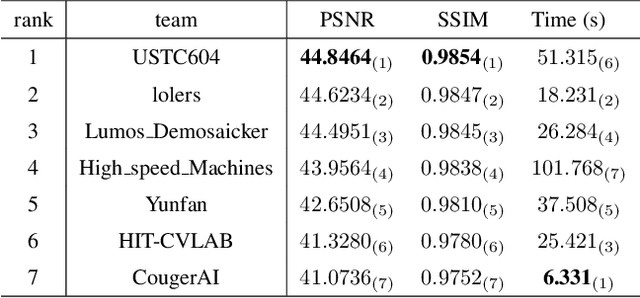
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
ForgeryGPT: Multimodal Large Language Model For Explainable Image Forgery Detection and Localization
Oct 14, 2024



Multimodal Large Language Models (MLLMs), such as GPT4o, have shown strong capabilities in visual reasoning and explanation generation. However, despite these strengths, they face significant challenges in the increasingly critical task of Image Forgery Detection and Localization (IFDL). Moreover, existing IFDL methods are typically limited to the learning of low-level semantic-agnostic clues and merely provide a single outcome judgment. To tackle these issues, we propose ForgeryGPT, a novel framework that advances the IFDL task by capturing high-order forensics knowledge correlations of forged images from diverse linguistic feature spaces, while enabling explainable generation and interactive dialogue through a newly customized Large Language Model (LLM) architecture. Specifically, ForgeryGPT enhances traditional LLMs by integrating the Mask-Aware Forgery Extractor, which enables the excavating of precise forgery mask information from input images and facilitating pixel-level understanding of tampering artifacts. The Mask-Aware Forgery Extractor consists of a Forgery Localization Expert (FL-Expert) and a Mask Encoder, where the FL-Expert is augmented with an Object-agnostic Forgery Prompt and a Vocabulary-enhanced Vision Encoder, allowing for effectively capturing of multi-scale fine-grained forgery details. To enhance its performance, we implement a three-stage training strategy, supported by our designed Mask-Text Alignment and IFDL Task-Specific Instruction Tuning datasets, which align vision-language modalities and improve forgery detection and instruction-following capabilities. Extensive experiments demonstrate the effectiveness of the proposed method.
Unveiling Language Skills under Circuits
Oct 02, 2024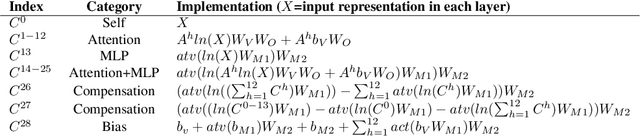
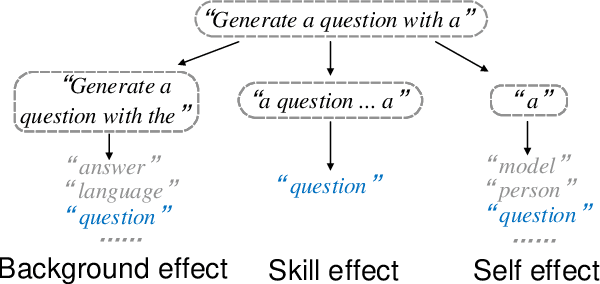


The exploration of language skills in language models (LMs) has always been one of the central goals in mechanistic interpretability. However, existing circuit analyses often fall short in representing the full functional scope of these models, primarily due to the exclusion of Feed-Forward layers. Additionally, isolating the effect of a single language skill from a text, which inherently involves multiple entangled skills, poses a significant challenge. To address these gaps, we introduce a novel concept, Memory Circuit, a minimum unit that fully and independently manipulates the memory-reading functionality of a language model, and disentangle the transformer model precisely into a circuit graph which is an ensemble of paths connecting different memory circuits. Based on this disentanglement, we identify salient circuit paths, named as skill paths, responsible for three crucial language skills, i.e., the Previous Token Skill, Induction Skill and In-Context Learning (ICL) Skill, leveraging causal effect estimation through interventions and counterfactuals. Our experiments on various datasets confirm the correspondence between our identified skill paths and language skills, and validate three longstanding hypotheses: 1) Language skills are identifiable through circuit dissection; 2) Simple language skills reside in shallow layers, whereas complex language skills are found in deeper layers; 3) Complex language skills are formed on top of simpler language skills. Our codes are available at: https://github.com/Zodiark-ch/Language-Skill-of-LLMs.
DemosaicFormer: Coarse-to-Fine Demosaicing Network for HybridEVS Camera
Jun 12, 2024



Hybrid Event-Based Vision Sensor (HybridEVS) is a novel sensor integrating traditional frame-based and event-based sensors, offering substantial benefits for applications requiring low-light, high dynamic range, and low-latency environments, such as smartphones and wearable devices. Despite its potential, the lack of Image signal processing (ISP) pipeline specifically designed for HybridEVS poses a significant challenge. To address this challenge, in this study, we propose a coarse-to-fine framework named DemosaicFormer which comprises coarse demosaicing and pixel correction. Coarse demosaicing network is designed to produce a preliminary high-quality estimate of the RGB image from the HybridEVS raw data while the pixel correction network enhances the performance of image restoration and mitigates the impact of defective pixels. Our key innovation is the design of a Multi-Scale Gating Module (MSGM) applying the integration of cross-scale features, which allows feature information to flow between different scales. Additionally, the adoption of progressive training and data augmentation strategies further improves model's robustness and effectiveness. Experimental results show superior performance against the existing methods both qualitatively and visually, and our DemosaicFormer achieves the best performance in terms of all the evaluation metrics in the MIPI 2024 challenge on Demosaic for Hybridevs Camera. The code is available at https://github.com/QUEAHREN/DemosaicFormer.
Quantifying Emergence in Large Language Models
May 21, 2024Emergence, broadly conceptualized as the ``intelligent'' behaviors of LLMs, has recently been studied and proved challenging to quantify due to the lack of a measurable definition. Most commonly, it has been estimated statistically through model performances across extensive datasets and tasks, which consumes significant resources. In addition, such estimation is difficult to interpret and may not accurately reflect the models' intrinsic emergence. In this work, we propose a quantifiable solution for estimating emergence. Inspired by emergentism in dynamics, we quantify the strength of emergence by comparing the entropy reduction of the macroscopic (semantic) level with that of the microscopic (token) level, both of which are derived from the representations within the transformer block. Using a low-cost estimator, our quantification method demonstrates consistent behaviors across a suite of LMs (GPT-2, GEMMA, etc.) under both in-context learning (ICL) and natural sentences. Empirical results show that (1) our method gives consistent measurements which align with existing observations based on performance metrics, validating the effectiveness of our emergence quantification; (2) our proposed metric uncovers novel emergence patterns such as the correlations between the variance of our metric and the number of ``shots'' in ICL, which further suggests a new way of interpreting hallucinations in LLMs; (3) we offer a potential solution towards estimating the emergence of larger and closed-resource LMs via smaller LMs like GPT-2. Our codes are available at: https://github.com/Zodiark-ch/Emergence-of-LLMs/.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024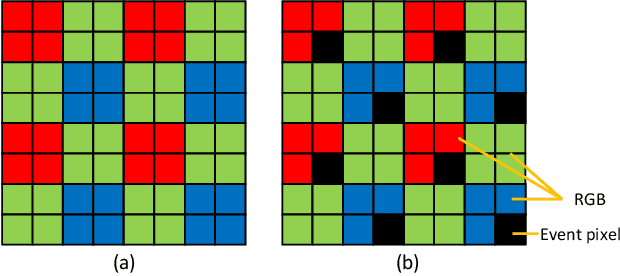
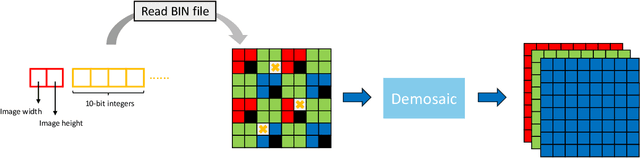

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Deep RAW Image Super-Resolution. A NTIRE 2024 Challenge Survey
Apr 24, 2024
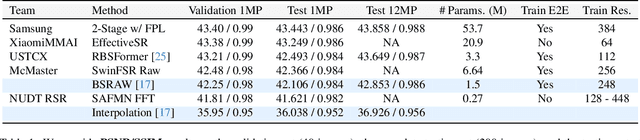
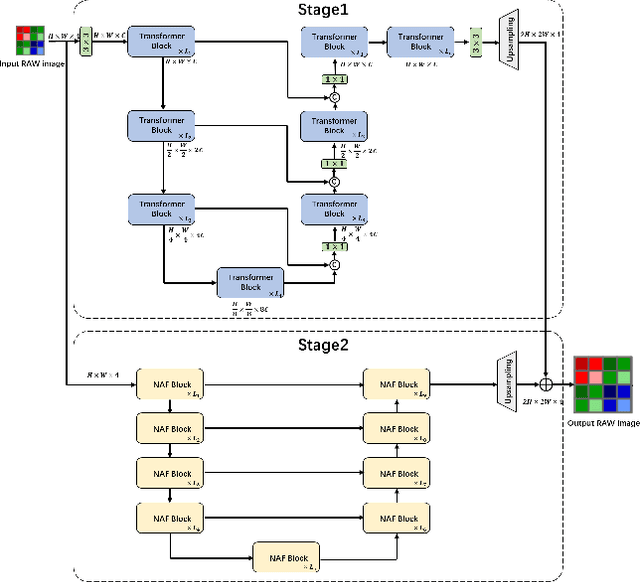
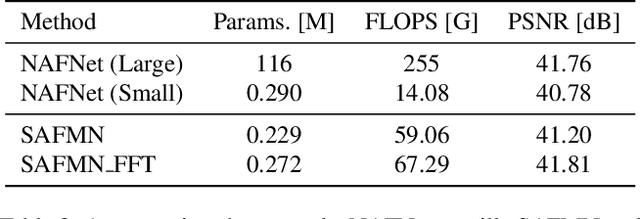
This paper reviews the NTIRE 2024 RAW Image Super-Resolution Challenge, highlighting the proposed solutions and results. New methods for RAW Super-Resolution could be essential in modern Image Signal Processing (ISP) pipelines, however, this problem is not as explored as in the RGB domain. Th goal of this challenge is to upscale RAW Bayer images by 2x, considering unknown degradations such as noise and blur. In the challenge, a total of 230 participants registered, and 45 submitted results during thee challenge period. The performance of the top-5 submissions is reviewed and provided here as a gauge for the current state-of-the-art in RAW Image Super-Resolution.