 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Performance of Generative Pre-trained Transformer in Simulating Depressed Individuals on the Standardized Depressive Symptom Scale
Jul 17, 2023



Background: Depression is a common mental disorder with societal and economic burden. Current diagnosis relies on self-reports and assessment scales, which have reliability issues. Objective approaches are needed for diagnosing depression. Objective: Evaluate the potential of GPT technology in diagnosing depression. Assess its ability to simulate individuals with depression and investigate the influence of depression scales. Methods: Three depression-related assessment tools (HAMD-17, SDS, GDS-15) were used. Two experiments simulated GPT responses to normal individuals and individuals with depression. Compare GPT's responses with expected results, assess its understanding of depressive symptoms, and performance differences under different conditions. Results: GPT's performance in depression assessment was evaluated. It aligned with scoring criteria for both individuals with depression and normal individuals. Some performance differences were observed based on depression severity. GPT performed better on scales with higher sensitivity. Conclusion: GPT accurately simulates individuals with depression and normal individuals during depression-related assessments. Deviations occur when simulating different degrees of depression, limiting understanding of mild and moderate cases. GPT performs better on scales with higher sensitivity, indicating potential for developing more effective depression scales. GPT has important potential in depression assessment, supporting clinicians and patients.
Multi-Slice Dense-Sparse Learning for Efficient Liver and Tumor Segmentation
Aug 15, 2021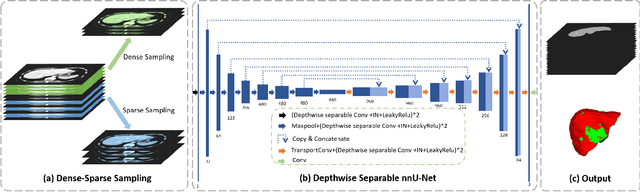
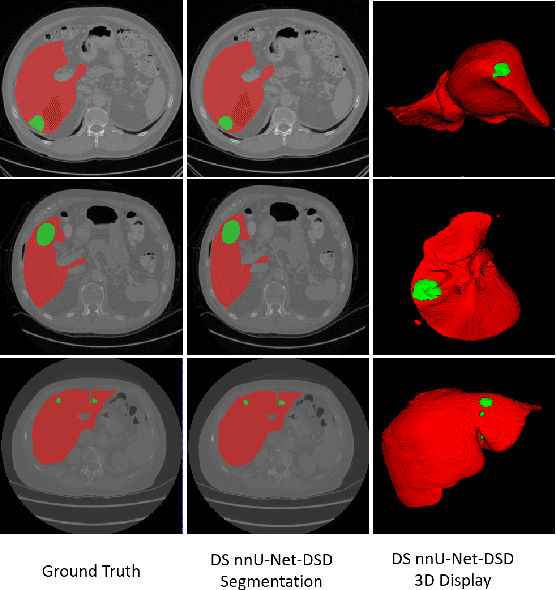
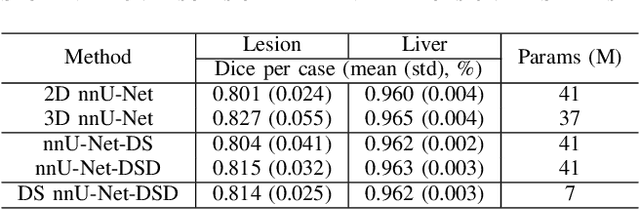
Accurate automatic liver and tumor segmentation plays a vital role in treatment planning and disease monitoring. Recently, deep convolutional neural network (DCNNs) has obtained tremendous success in 2D and 3D medical image segmentation. However, 2D DCNNs cannot fully leverage the inter-slice information, while 3D DCNNs are computationally expensive and memory intensive. To address these issues, we first propose a novel dense-sparse training flow from a data perspective, in which, densely adjacent slices and sparsely adjacent slices are extracted as inputs for regularizing DCNNs, thereby improving the model performance. Moreover, we design a 2.5D light-weight nnU-Net from a network perspective, in which, depthwise separable convolutions are adopted to improve the efficiency. Extensive experiments on the LiTS dataset have demonstrated the superiority of the proposed method.
Learning to Navigate in Indoor Environments: from Memorizing to Reasoning
Apr 21, 2019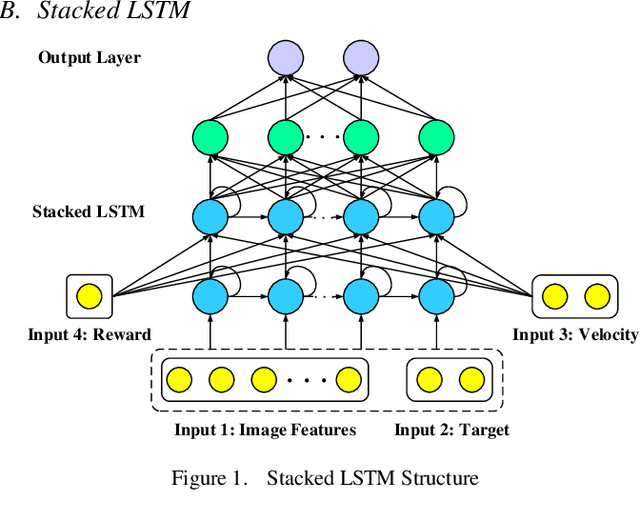
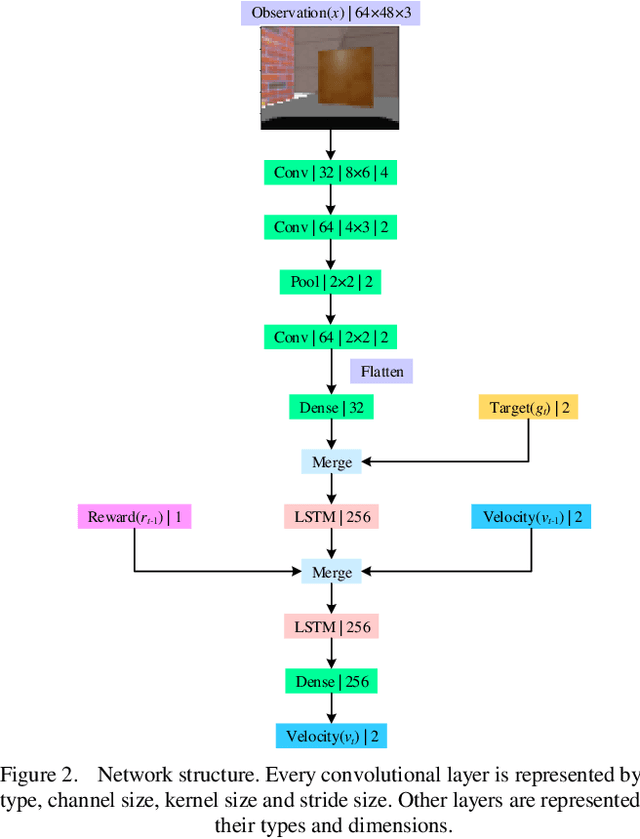
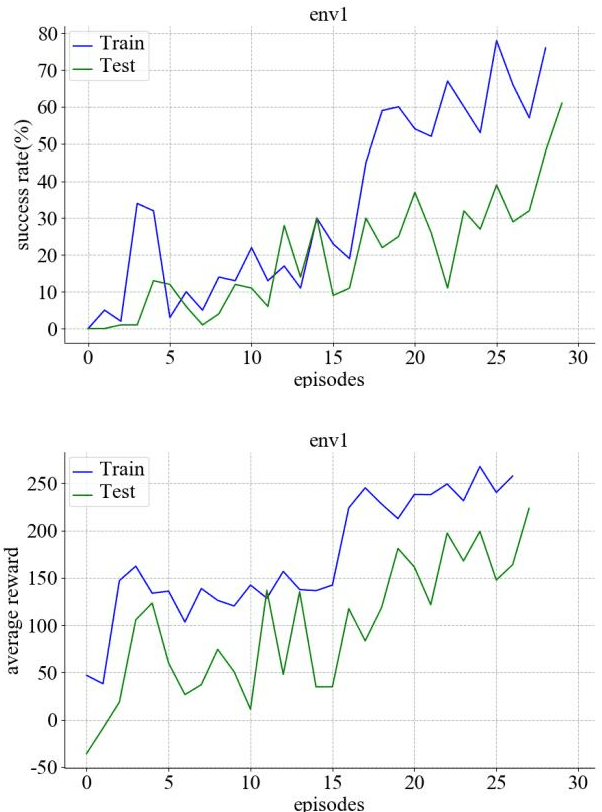
Autonomous navigation is an essential capability of smart mobility for mobile robots. Traditional methods must have the environment map to plan a collision-free path in workspace. Deep reinforcement learning (DRL) is a promising technique to realize the autonomous navigation task without a map, with which deep neural network can fit the mapping from observation to reasonable action through explorations. It should not only memorize the trained target, but more importantly, the planner can reason out the unseen goal. We proposed a new motion planner based on deep reinforcement learning that can arrive at new targets that have not been trained before in the indoor environment with RGB image and odometry only. The model has a structure of stacked Long Short-Term memory (LSTM). Finally, experiments were implemented in both simulated and real environments. The source code is available: https://github.com/marooncn/navbot.
Using RGB Image as Visual Input for Mapless Robot Navigation
Apr 16, 2019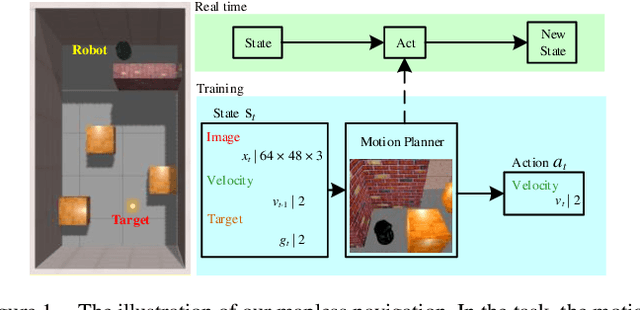
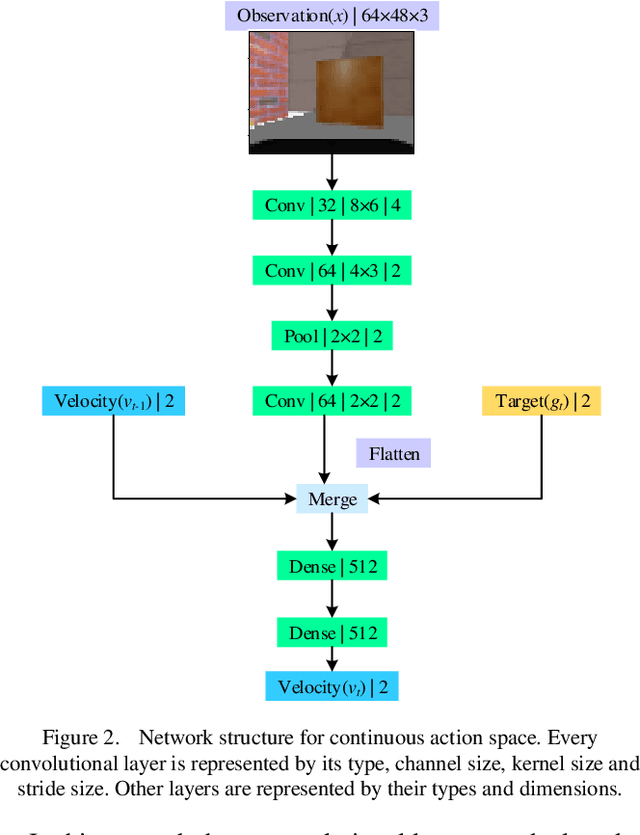
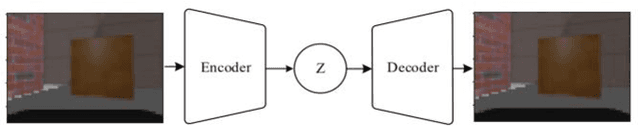
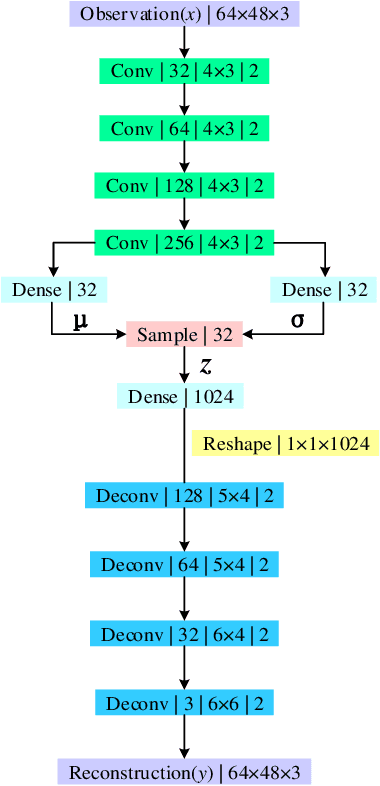
Robot navigation in mapless environment is one of the essential problems and challenges in mobile robots. Deep reinforcement learning is a promising technique to tackle the task of mapless navigation. Since reinforcement learning requires a lot of explorations, it is usually necessary to train the agent in the simulator and then migrate to the real environment. The big reality gap makes RGB image, the most common visual sensor, rarely used. In this paper we present a learning-based mapless motion planner by taking RGB images as visual inputs. Many parameters in end-to-end navigation network taking RGB images as visual input are used to extract visual features. Therefore, we decouple visual features extracted module from the reinforcement learning network to reduce the need of interactions between agent and environment. We use Variational Autoencoder (VAE) to encode the image, and input the obtained latent vector as low-dimensional visual features into the network together with the target and motion information, so that the sampling efficiency of the agent is greatly improved. We built simulation environment as robot navigation environment for algorithm comparison. In the test environment, the proposed method was compared with the end-to-end network, which proved its effectiveness and efficiency. The source code is available: https://github.com/marooncn/navbot.
Plantbot: A New ROS-based Robot Platform for Fast Building and Developing
Apr 08, 2018


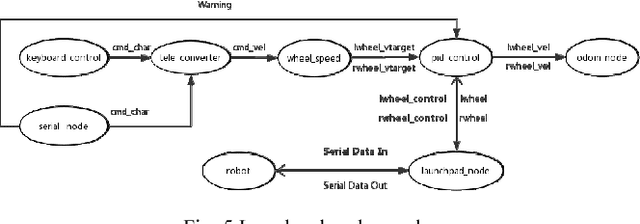
In recent years, the Robot Operating System (ROS) is developing rapidly and has been widely used in robotics research because of its flexible, open source, and extensive advantages. In scientific research, the corresponding hardware platform is indispensable for the experiment. In the field of mobile robots, PR2, Turtlebot2, and Fetch are commonly used as research platforms. Although these platforms are fully functional and widely used, they are expensive and bulky. What\u2019s more, these robots are not easily redesigned and expanded according to requirements. To overcome these limitations, we propose Plantbot, an easy-building, low-cost robot platform that can be redesigned and expanded according to requirements. It can be applied to not only fast algorithm verification, but also simple factory inspection and ROS teaching. This article describes this robot platform from several aspects such as hardware design, kinematics, and control methods. At last two experiments, SLAM and Navigation, on the robot platform are performed. The source code of this platform is available.