 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Language Skills under Circuits
Paper and Code
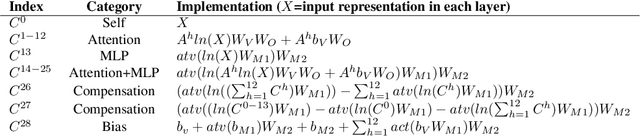


The exploration of language skills in language models (LMs) has always been one of the central goals in mechanistic interpretability. However, existing circuit analyses often fall short in representing the full functional scope of these models, primarily due to the exclusion of Feed-Forward layers. Additionally, isolating the effect of a single language skill from a text, which inherently involves multiple entangled skills, poses a significant challenge. To address these gaps, we introduce a novel concept, Memory Circuit, a minimum unit that fully and independently manipulates the memory-reading functionality of a language model, and disentangle the transformer model precisely into a circuit graph which is an ensemble of paths connecting different memory circuits. Based on this disentanglement, we identify salient circuit paths, named as skill paths, responsible for three crucial language skills, i.e., the Previous Token Skill, Induction Skill and In-Context Learning (ICL) Skill, leveraging causal effect estimation through interventions and counterfactuals. Our experiments on various datasets confirm the correspondence between our identified skill paths and language skills, and validate three longstanding hypotheses: 1) Language skills are identifiable through circuit dissection; 2) Simple language skills reside in shallow layers, whereas complex language skills are found in deeper layers; 3) Complex language skills are formed on top of simpler language skills. Our codes are available at: https://github.com/Zodiark-ch/Language-Skill-of-LLMs.