 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Universal Speech Attributes Modeling for Zero-Shot Multilingual Spoken Keyword Recognition
Paper and Code
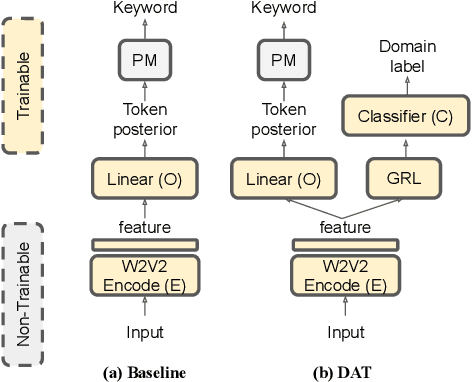

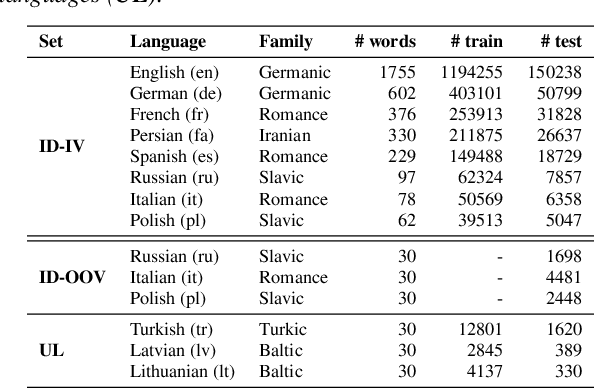

We propose a novel language-universal approach to end-to-end automatic spoken keyword recognition (SKR) leveraging upon (i) a self-supervised pre-trained model, and (ii) a set of universal speech attributes (manner and place of articulation). Specifically, Wav2Vec2.0 is used to generate robust speech representations, followed by a linear output layer to produce attribute sequences. A non-trainable pronunciation model then maps sequences of attributes into spoken keywords in a multilingual setting. Experiments on the Multilingual Spoken Words Corpus show comparable performances to character- and phoneme-based SKR in seen languages. The inclusion of domain adversarial training (DAT) improves the proposed framework, outperforming both character- and phoneme-based SKR approaches with 13.73% and 17.22% relative word error rate (WER) reduction in seen languages, and achieves 32.14% and 19.92% WER reduction for unseen languages in zero-shot settings.