 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explicit Consistency-Preserving Loss Function for Phase Reconstruction and Speech Enhancement
Paper and Code
Sep 24, 2024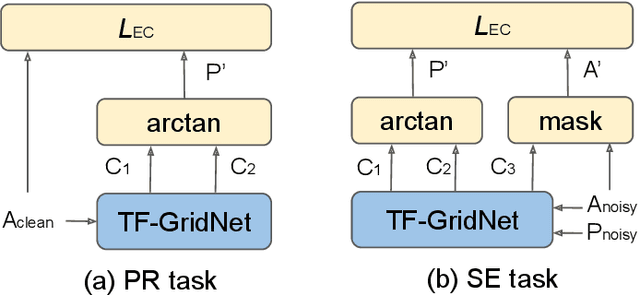
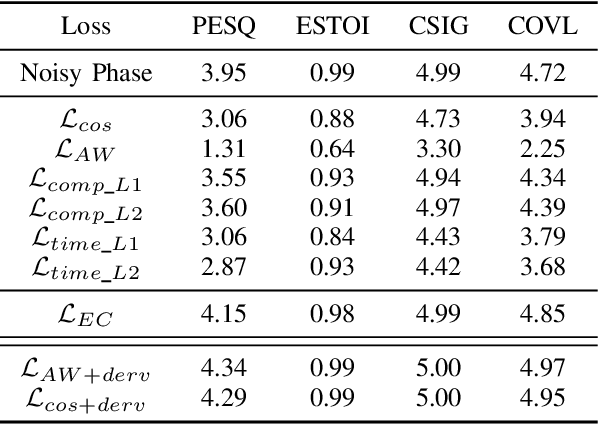

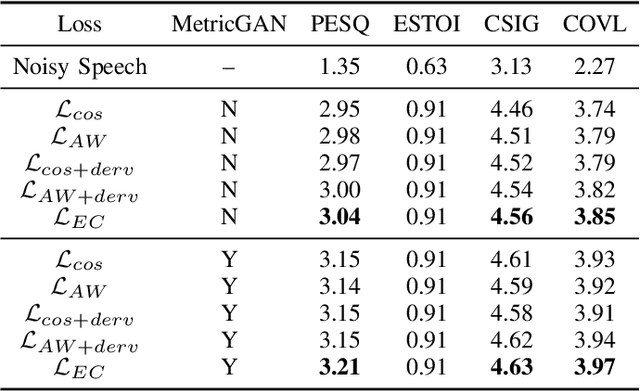
In this work, we propose a novel consistency-preserving loss function for recovering the phase information in the context of phase reconstruction (PR) and speech enhancement (SE). Different from conventional techniques that directly estimate the phase using a deep model, our idea is to exploit ad-hoc constraints to directly generate a consistent pair of magnitude and phase. Specifically, the proposed loss forces a set of complex numbers to be a consistent short-time Fourier transform (STFT) representation, i.e., to be the spectrogram of a real signal. Our approach thus avoids the difficulty of estimating the original phase, which is highly unstructured and sensitive to time shift. The influence of our proposed loss is first assessed on a PR task, experimentally demonstrating that our approach is viable. Next, we show its effectiveness on an SE task, using both the VB-DMD and WSJ0-CHiME3 data sets. On VB-DMD, our approach is competitive with conventional solutions. On the challenging WSJ0-CHiME3 set, the proposed framework compares favourably over those techniques that explicitly estimate the phase.