 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation on Combining Geometry and Consistency Constraints into Phase Estimation for Speech Enhancement
Jul 02, 2025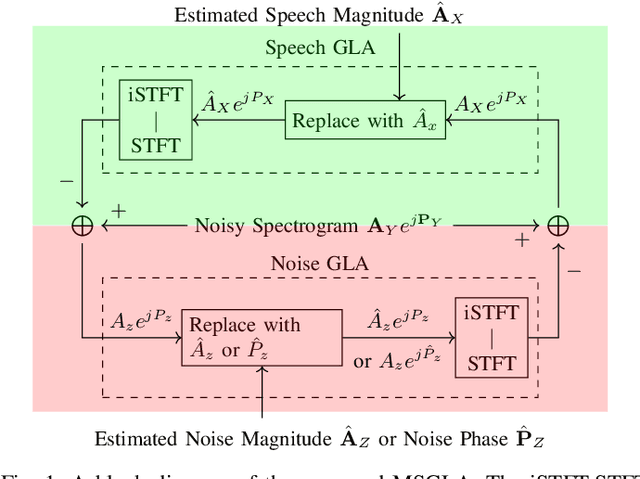
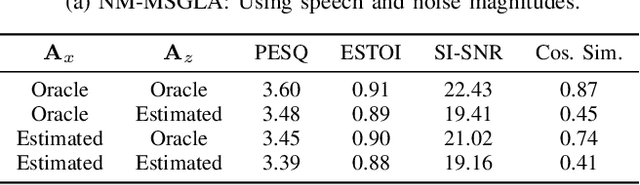
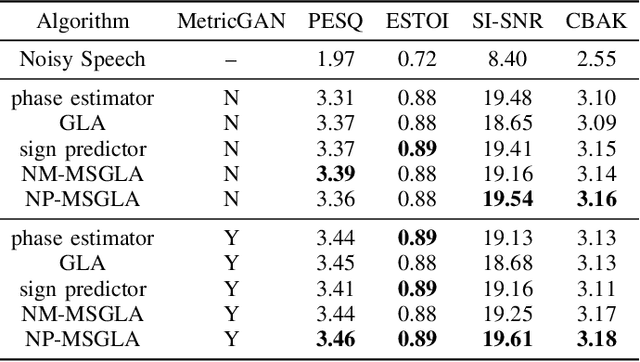
We propose a novel iterative phase estimation framework, termed multi-source Griffin-Lim algorithm (MSGLA), for speech enhancement (SE) under additive noise conditions. The core idea is to leverage the ad-hoc consistency constraint of complex-valued short-time Fourier transform (STFT) spectrograms to address the sign ambiguity challenge commonly encountered in geometry-based phase estimation. Furthermore, we introduce a variant of the geometric constraint framework based on the law of sines and cosines, formulating a new phase reconstruction algorithm using noise phase estimates. We first validate the proposed technique through a series of oracle experiments, demonstrating its effectiveness under ideal conditions. We then evaluate its performance on the VB-DMD and WSJ0-CHiME3 data sets, and show that the proposed MSGLA variants match well or slightly outperform existing algorithms, including direct phase estimation and DNN-based sign prediction, especially in terms of background noise suppression.
An Explicit Consistency-Preserving Loss Function for Phase Reconstruction and Speech Enhancement
Sep 24, 2024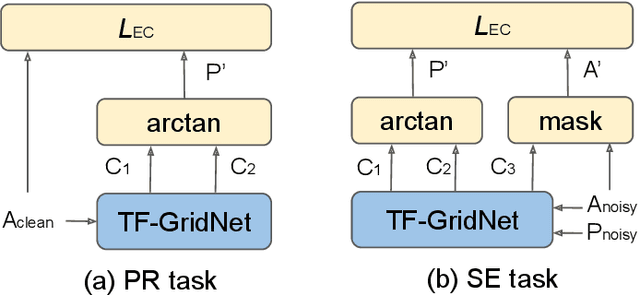
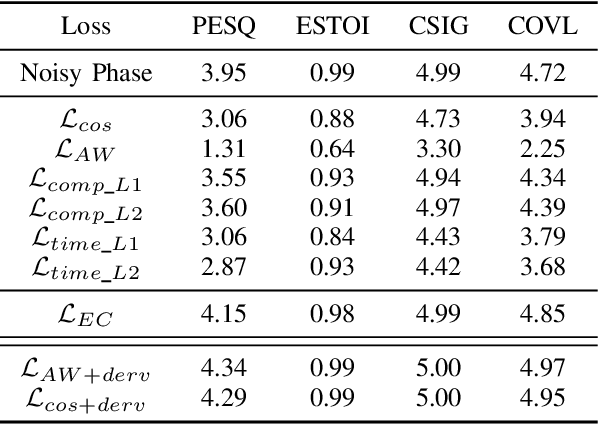

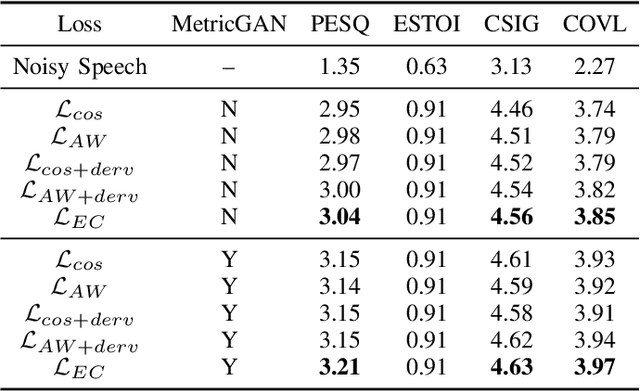
In this work, we propose a novel consistency-preserving loss function for recovering the phase information in the context of phase reconstruction (PR) and speech enhancement (SE). Different from conventional techniques that directly estimate the phase using a deep model, our idea is to exploit ad-hoc constraints to directly generate a consistent pair of magnitude and phase. Specifically, the proposed loss forces a set of complex numbers to be a consistent short-time Fourier transform (STFT) representation, i.e., to be the spectrogram of a real signal. Our approach thus avoids the difficulty of estimating the original phase, which is highly unstructured and sensitive to time shift. The influence of our proposed loss is first assessed on a PR task, experimentally demonstrating that our approach is viable. Next, we show its effectiveness on an SE task, using both the VB-DMD and WSJ0-CHiME3 data sets. On VB-DMD, our approach is competitive with conventional solutions. On the challenging WSJ0-CHiME3 set, the proposed framework compares favourably over those techniques that explicitly estimate the phase.
Differentially Private Adapters for Parameter Efficient Acoustic Modeling
May 19, 2023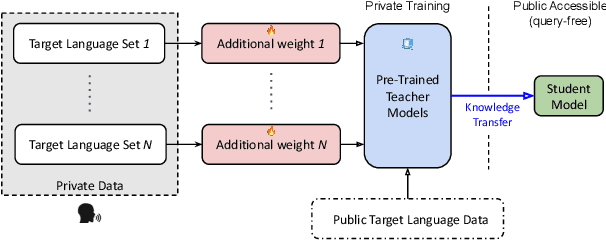
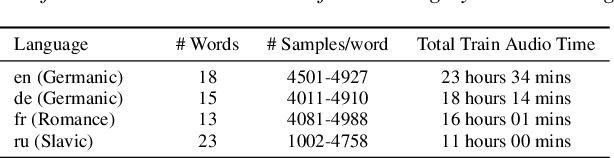
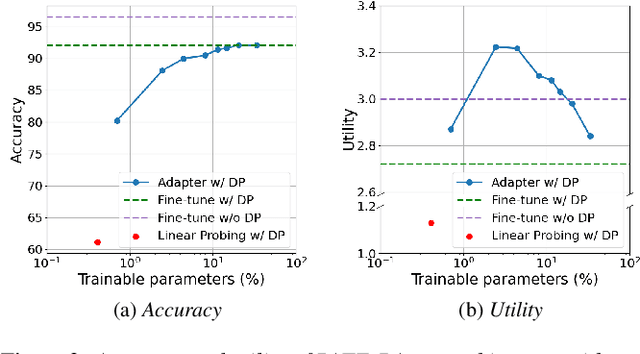
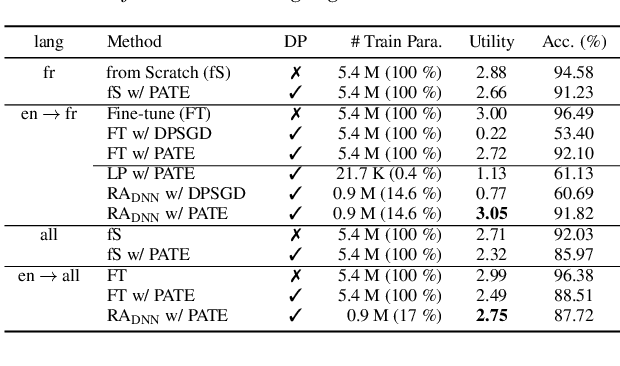
In this work, we devise a parameter-efficient solution to bring differential privacy (DP) guarantees into adaptation of a cross-lingual speech classifier. We investigate a new frozen pre-trained adaptation framework for DP-preserving speech modeling without full model fine-tuning. First, we introduce a noisy teacher-student ensemble into a conventional adaptation scheme leveraging a frozen pre-trained acoustic model and attain superior performance than DP-based stochastic gradient descent (DPSGD). Next, we insert residual adapters (RA) between layers of the frozen pre-trained acoustic model. The RAs reduce training cost and time significantly with a negligible performance drop. Evaluated on the open-access Multilingual Spoken Words (MLSW) dataset, our solution reduces the number of trainable parameters by 97.5% using the RAs with only a 4% performance drop with respect to fine-tuning the cross-lingual speech classifier while preserving DP guarantees.