 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Phonetic Pretraining for End-to-end Utterance-level Language and Speaker Recognition
Paper and Code
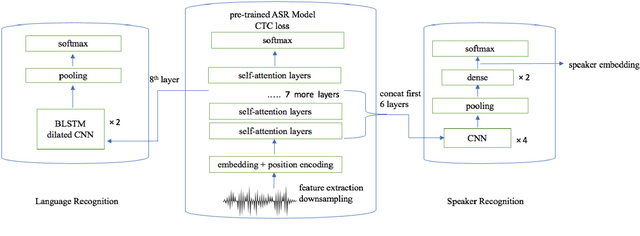
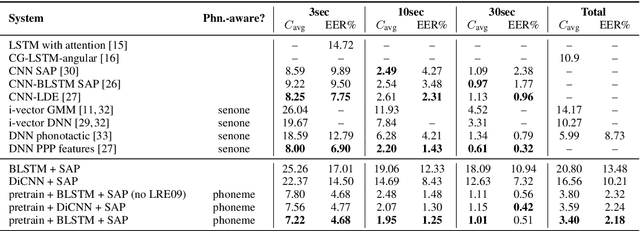
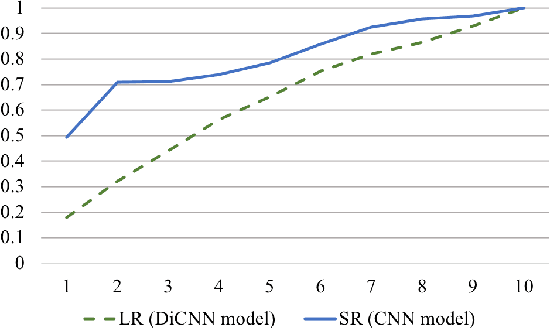
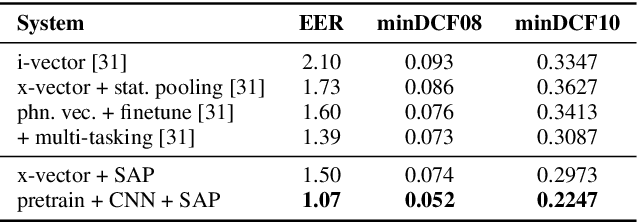
Pretrained contextual word representations in NLP have greatly improved performance on various downstream tasks. For speech, we propose contextual frame representations that capture phonetic information at the acoustic frame level and can be used for utterance-level language, speaker, and speech recognition. These representations come from the frame-wise intermediate representations of an end-to-end, self-attentive ASR model (SAN-CTC) on spoken utterances. We first train the model on the Fisher English corpus with context-independent phoneme labels, then use its representations at inference time as features for task-specific models on the NIST LRE07 closed-set language recognition task and a Fisher speaker recognition task, giving significant improvements over the state-of-the-art on both (e.g., language EER of 4.68% on 3sec utterances, 23% relative reduction in speaker EER). Results remain competitive when using a novel dilated convolutional model for language recognition, or when ASR pretraining is done with character labels only.