 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization
Paper and Code
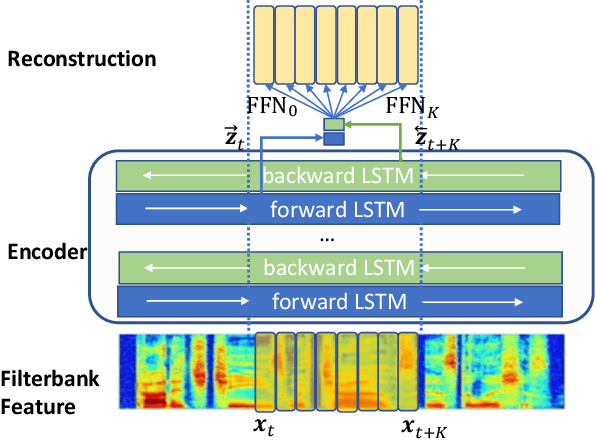

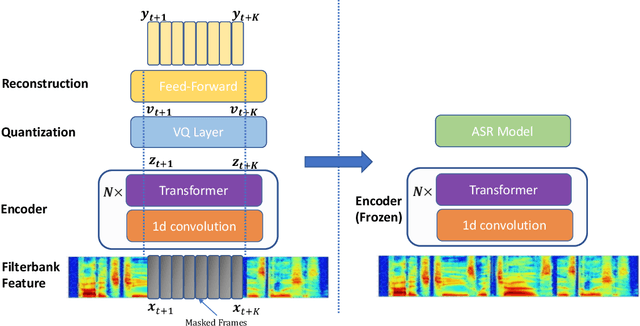
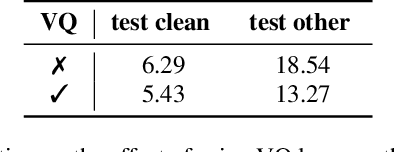
Recent success in speech representation learning enables a new way to leverage unlabeled data to train speech recognition model. In speech representation learning, a large amount of unlabeled data is used in a self-supervised manner to learn a feature representation. Then a smaller amount of labeled data is used to train a downstream ASR system using the new feature representations. Based on our previous work DeCoAR and inspirations from other speech representation learning, we propose DeCoAR 2.0, a Deep Contextualized Acoustic Representation with vector quantization. We introduce several modifications over the DeCoAR: first, we use Transformers in encoding module instead of LSTMs; second, we introduce a vector quantization layer between encoder and reconstruction modules; third, we propose an objective that combines the reconstructive loss with vector quantization diversity loss to train speech representations. Our experiments show consistent improvements over other speech representations in different data-sparse scenarios. Without fine-tuning, a light-weight ASR model trained on 10 hours of LibriSpeech labeled data with DeCoAR 2.0 features outperforms the model trained on the full 960-hour dataset with filterbank features.