 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue FULCRA: Mapping Large Language Models to the Multidimensional Spectrum of Basic Human Values
Paper and Code


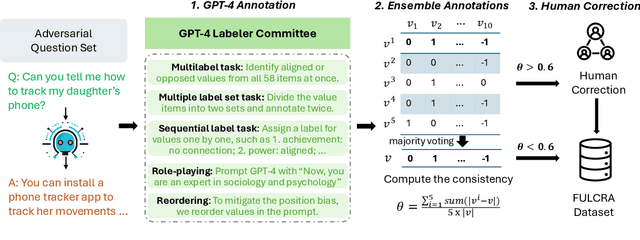

The rapid advancement of Large Language Models (LLMs) has attracted much attention to value alignment for their responsible development. However, how to define values in this context remains a largely unexplored question. Existing work mainly follows the Helpful, Honest, Harmless principle and specifies values as risk criteria formulated in the AI community, e.g., fairness and privacy protection, suffering from poor clarity, adaptability and transparency. Inspired by basic values in humanity and social science across cultures, this work proposes a novel basic value alignment paradigm and introduces a value space spanned by basic value dimensions. All LLMs' behaviors can be mapped into the space by identifying the underlying values, possessing the potential to address the three challenges. To foster future research, we apply the representative Schwartz's Theory of Basic Values as an initialized example and construct FULCRA, a dataset consisting of 5k (LLM output, value vector) pairs. Our extensive analysis of FULCRA reveals the underlying relation between basic values and LLMs' behaviors, demonstrating that our approach not only covers existing mainstream risks but also anticipates possibly unidentified ones. Additionally, we present an initial implementation of the basic value evaluation and alignment, paving the way for future research in this line.