 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch for Efficient Large Language Models
Paper and Code
Sep 25, 2024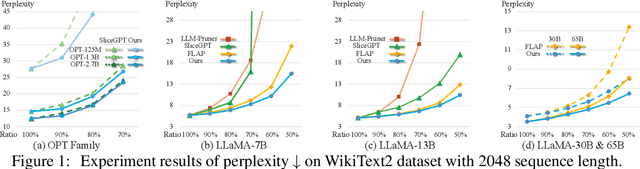
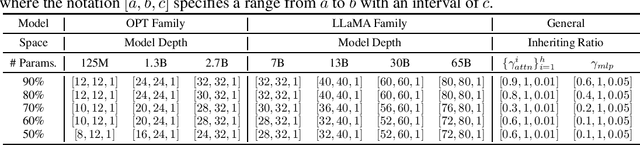
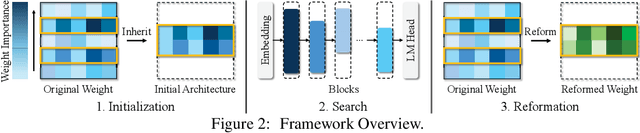
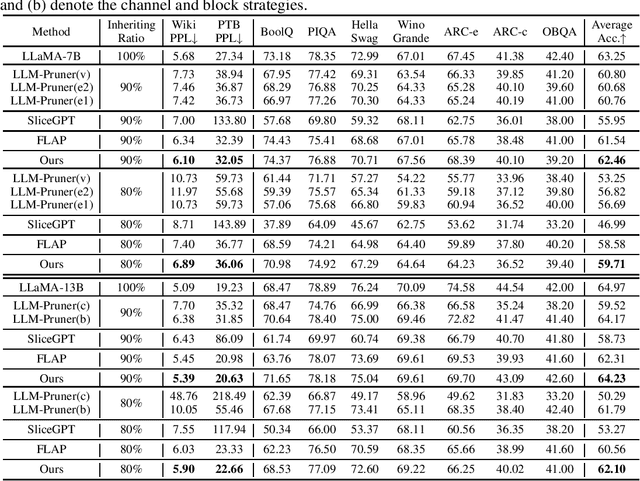
Large Language Models (LLMs) have long held sway in the realms of artificial intelligence research. Numerous efficient techniques, including weight pruning, quantization, and distillation, have been embraced to compress LLMs, targeting memory reduction and inference acceleration, which underscore the redundancy in LLMs. However, most model compression techniques concentrate on weight optimization, overlooking the exploration of optimal architectures. Besides, traditional architecture search methods, limited by the elevated complexity with extensive parameters, struggle to demonstrate their effectiveness on LLMs. In this paper, we propose a training-free architecture search framework to identify optimal subnets that preserve the fundamental strengths of the original LLMs while achieving inference acceleration. Furthermore, after generating subnets that inherit specific weights from the original LLMs, we introduce a reformation algorithm that utilizes the omitted weights to rectify the inherited weights with a small amount of calibration data. Compared with SOTA training-free structured pruning works that can generate smaller networks, our method demonstrates superior performance across standard benchmarks. Furthermore, our generated subnets can directly reduce the usage of GPU memory and achieve inference acceleration.