 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainFusion2.0: Temporal-Spatial Awareness and Hardware-Efficient Block-wise Sparse Attention
Dec 30, 2025In video and image generation tasks, Diffusion Transformer (DiT) models incur extremely high computational costs due to attention mechanisms, which limits their practical applications. Furthermore, with hardware advancements, a wide range of devices besides graphics processing unit (GPU), such as application-specific integrated circuit (ASIC), have been increasingly adopted for model inference. Sparse attention, which leverages the inherent sparsity of attention by skipping computations for insignificant tokens, is an effective approach to mitigate computational costs. However, existing sparse attention methods have two critical limitations: the overhead of sparse pattern prediction and the lack of hardware generality, as most of these methods are designed for GPU. To address these challenges, this study proposes RainFusion2.0, which aims to develop an online adaptive, hardware-efficient, and low-overhead sparse attention mechanism to accelerate both video and image generative models, with robust performance across diverse hardware platforms. Key technical insights include: (1) leveraging block-wise mean values as representative tokens for sparse mask prediction; (2) implementing spatiotemporal-aware token permutation; and (3) introducing a first-frame sink mechanism specifically designed for video generation scenarios. Experimental results demonstrate that RainFusion2.0 can achieve 80% sparsity while achieving an end-to-end speedup of 1.5~1.8x without compromising video quality. Moreover, RainFusion2.0 demonstrates effectiveness across various generative models and validates its generalization across diverse hardware platforms.
Fragmented Layer Grouping in GUI Designs Through Graph Learning Based on Multimodal Information
Dec 07, 2024



Automatically constructing GUI groups of different granularities constitutes a critical intelligent step towards automating GUI design and implementation tasks. Specifically, in the industrial GUI-to-code process, fragmented layers may decrease the readability and maintainability of generated code, which can be alleviated by grouping semantically consistent fragmented layers in the design prototypes. This study aims to propose a graph-learning-based approach to tackle the fragmented layer grouping problem according to multi-modal information in design prototypes. Our graph learning module consists of self-attention and graph neural network modules. By taking the multimodal fused representation of GUI layers as input, we innovatively group fragmented layers by classifying GUI layers and regressing the bounding boxes of the corresponding GUI components simultaneously. Experiments on two real-world datasets demonstrate that our model achieves state-of-the-art performance. A further user study is also conducted to validate that our approach can assist an intelligent downstream tool in generating more maintainable and readable front-end code.
EGFE: End-to-end Grouping of Fragmented Elements in UI Designs with Multimodal Learning
Sep 18, 2023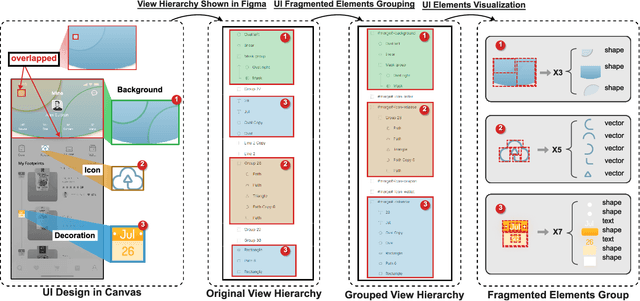
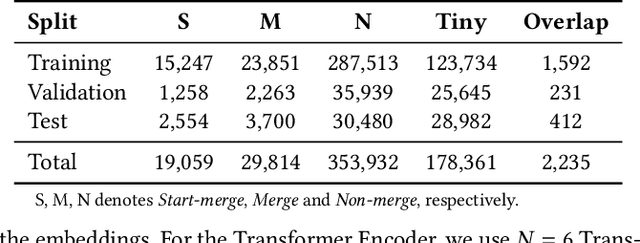
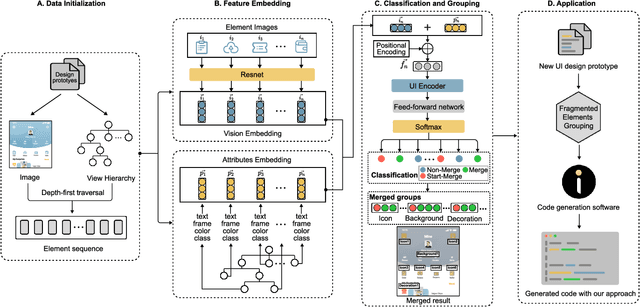
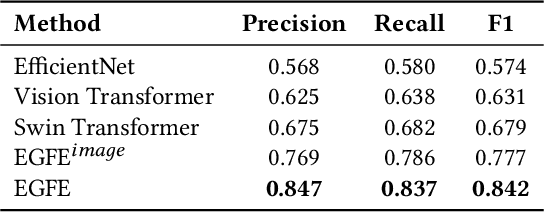
When translating UI design prototypes to code in industry, automatically generating code from design prototypes can expedite the development of applications and GUI iterations. However, in design prototypes without strict design specifications, UI components may be composed of fragmented elements. Grouping these fragmented elements can greatly improve the readability and maintainability of the generated code. Current methods employ a two-stage strategy that introduces hand-crafted rules to group fragmented elements. Unfortunately, the performance of these methods is not satisfying due to visually overlapped and tiny UI elements. In this study, we propose EGFE, a novel method for automatically End-to-end Grouping Fragmented Elements via UI sequence prediction. To facilitate the UI understanding, we innovatively construct a Transformer encoder to model the relationship between the UI elements with multi-modal representation learning. The evaluation on a dataset of 4606 UI prototypes collected from professional UI designers shows that our method outperforms the state-of-the-art baselines in the precision (by 29.75\%), recall (by 31.07\%), and F1-score (by 30.39\%) at edit distance threshold of 4. In addition, we conduct an empirical study to assess the improvement of the generated front-end code. The results demonstrate the effectiveness of our method on a real software engineering application. Our end-to-end fragmented elements grouping method creates opportunities for improving UI-related software engineering tasks.
UI Layers Group Detector: Grouping UI Layers via Text Fusion and Box Attention
Dec 07, 2022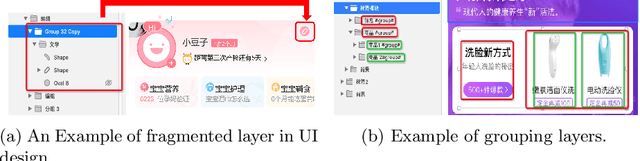
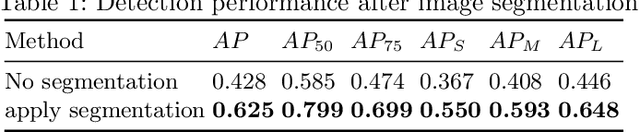

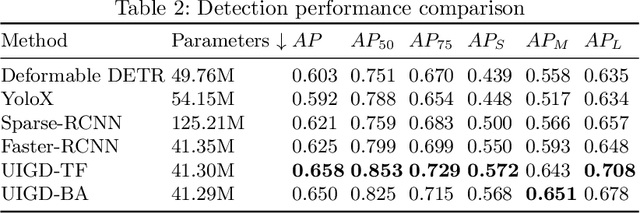
Graphic User Interface (GUI) is facing great demand with the popularization and prosperity of mobile apps. Automatic UI code generation from UI design draft dramatically simplifies the development process. However, the nesting layer structure in the design draft affects the quality and usability of the generated code. Few existing GUI automated techniques detect and group the nested layers to improve the accessibility of generated code. In this paper, we proposed our UI Layers Group Detector as a vision-based method that automatically detects images (i.e., basic shapes and visual elements) and text layers that present the same semantic meanings. We propose two plug-in components, text fusion and box attention, that utilize text information from design drafts as a priori information for group localization. We construct a large-scale UI dataset for training and testing, and present a data augmentation approach to boost the detection performance. The experiment shows that the proposed method achieves a decent accuracy regarding layers grouping.
ULDGNN: A Fragmented UI Layer Detector Based on Graph Neural Networks
Aug 13, 2022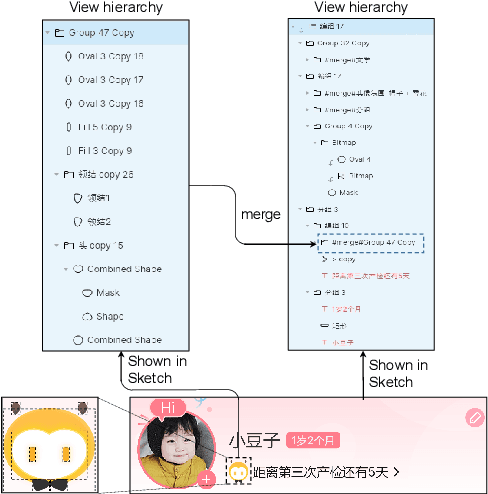
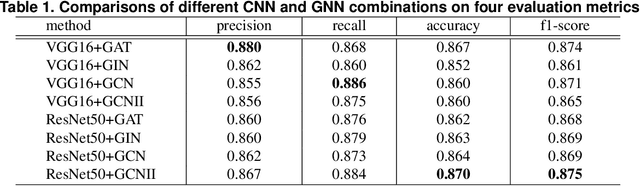
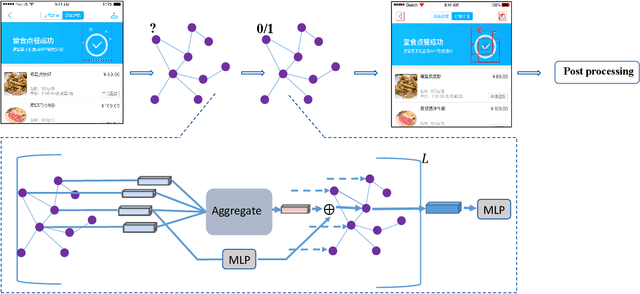

While some work attempt to generate front-end code intelligently from UI screenshots, it may be more convenient to utilize UI design drafts in Sketch which is a popular UI design software, because we can access multimodal UI information directly such as layers type, position, size, and visual images. However, fragmented layers could degrade the code quality without being merged into a whole part if all of them are involved in the code generation. In this paper, we propose a pipeline to merge fragmented layers automatically. We first construct a graph representation for the layer tree of a UI draft and detect all fragmented layers based on the visual features and graph neural networks. Then a rule-based algorithm is designed to merge fragmented layers. Through experiments on a newly constructed dataset, our approach can retrieve most fragmented layers in UI design drafts, and achieve 87% accuracy in the detection task, and the post-processing algorithm is developed to cluster associative layers under simple and general circumstances.
Zero Shot on the Cold-Start Problem: Model-Agnostic Interest Learning for Recommender Systems
Aug 31, 2021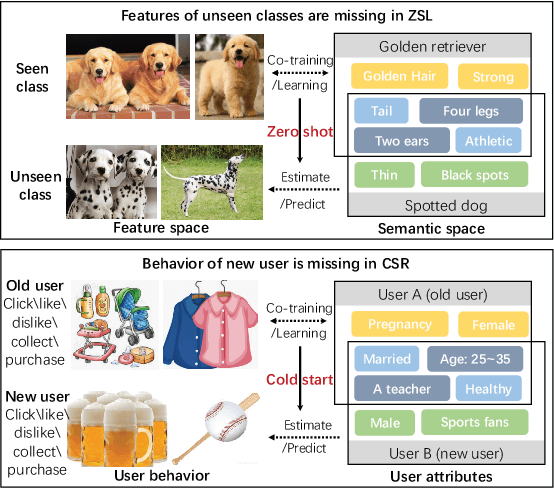
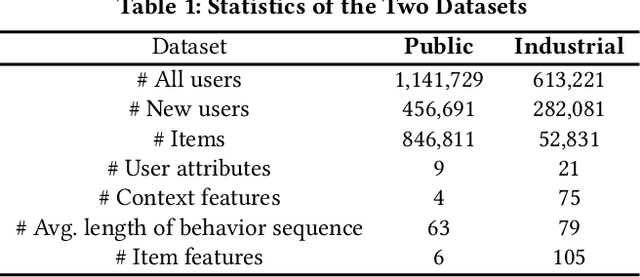
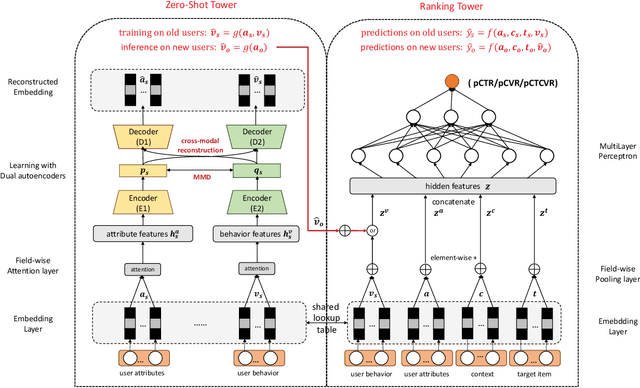

User behavior has been validated to be effective in revealing personalized preferences for commercial recommendations. However, few user-item interactions can be collected for new users, which results in a null space for their interests, i.e., the cold-start dilemma. In this paper, a two-tower framework, namely, the model-agnostic interest learning (MAIL) framework, is proposed to address the cold-start recommendation (CSR) problem for recommender systems. In MAIL, one unique tower is constructed to tackle the CSR from a zero-shot view, and the other tower focuses on the general ranking task. Specifically, the zero-shot tower first performs cross-modal reconstruction with dual auto-encoders to obtain virtual behavior data from highly aligned hidden features for new users; and the ranking tower can then output recommendations for users based on the completed data by the zero-shot tower. Practically, the ranking tower in MAIL is model-agnostic and can be implemented with any embedding-based deep models. Based on the co-training of the two towers, the MAIL presents an end-to-end method for recommender systems that shows an incremental performance improvement. The proposed method has been successfully deployed on the live recommendation system of NetEase Cloud Music to achieve a click-through rate improvement of 13% to 15% for millions of users. Offline experiments on real-world datasets also show its superior performance in CSR. Our code is available.
Inventory Control Involving Unknown Demand of Discrete Nonperishable Items - Analysis of a Newsvendor-based Policy
Oct 22, 2015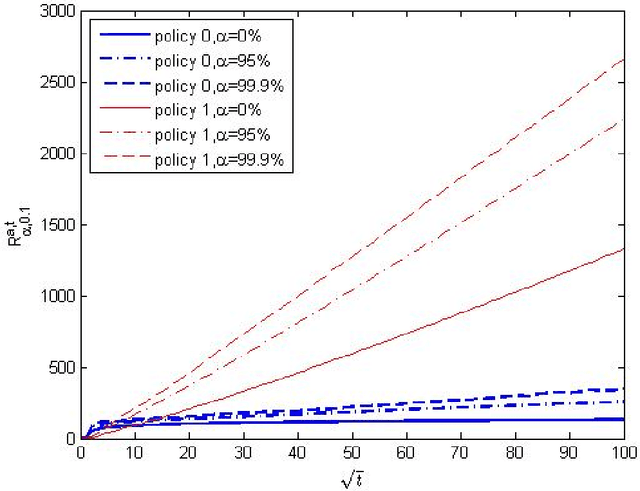
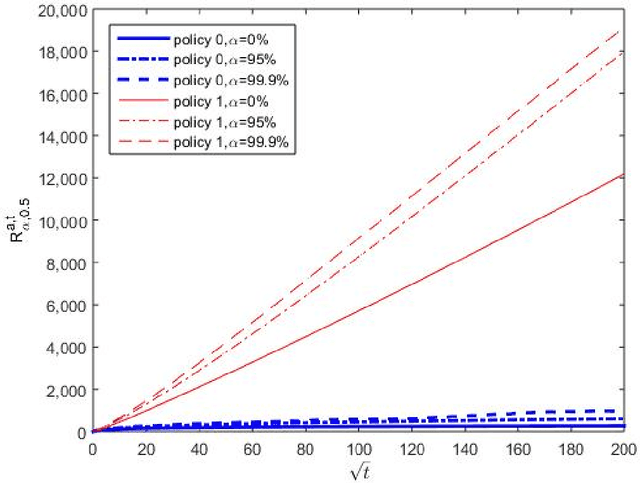

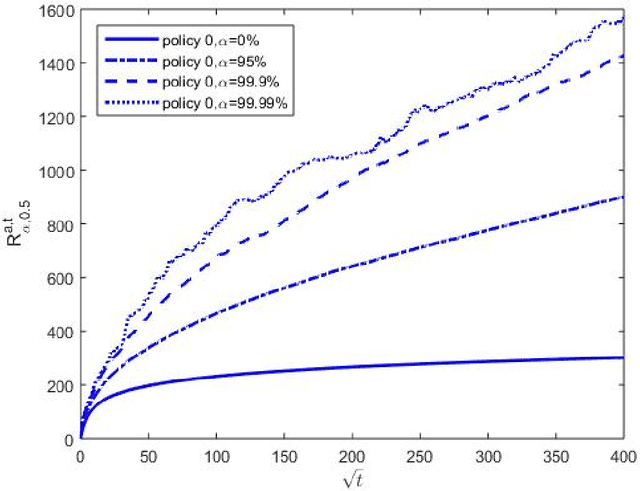
Inventory control with unknown demand distribution is considered, with emphasis placed on the case involving discrete nonperishable items. We focus on an adaptive policy which in every period uses, as much as possible, the optimal newsvendor ordering quantity for the empirical distribution learned up to that period. The policy is assessed using the regret criterion, which measures the price paid for ambiguity on demand distribution over $T$ periods. When there are guarantees on the latter's separation from the critical newsvendor parameter $\beta=b/(h+b)$, a constant upper bound on regret can be found. Without any prior information on the demand distribution, we show that the regret does not grow faster than the rate $T^{1/2+\epsilon}$ for any $\epsilon>0$. In view of a known lower bound, this is almost the best one could hope for. Simulation studies involving this along with other policies are also conducted.