 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFragmented Layer Grouping in GUI Designs Through Graph Learning Based on Multimodal Information
Dec 07, 2024



Automatically constructing GUI groups of different granularities constitutes a critical intelligent step towards automating GUI design and implementation tasks. Specifically, in the industrial GUI-to-code process, fragmented layers may decrease the readability and maintainability of generated code, which can be alleviated by grouping semantically consistent fragmented layers in the design prototypes. This study aims to propose a graph-learning-based approach to tackle the fragmented layer grouping problem according to multi-modal information in design prototypes. Our graph learning module consists of self-attention and graph neural network modules. By taking the multimodal fused representation of GUI layers as input, we innovatively group fragmented layers by classifying GUI layers and regressing the bounding boxes of the corresponding GUI components simultaneously. Experiments on two real-world datasets demonstrate that our model achieves state-of-the-art performance. A further user study is also conducted to validate that our approach can assist an intelligent downstream tool in generating more maintainable and readable front-end code.
An Artificial Intelligence Approach for Interpreting Creative Combinational Designs
May 08, 2024Combinational creativity, a form of creativity involving the blending of familiar ideas, is pivotal in design innovation. While most research focuses on how combinational creativity in design is achieved through blending elements, this study focuses on the computational interpretation, specifically identifying the 'base' and 'additive' components that constitute a creative design. To achieve this goal, the authors propose a heuristic algorithm integrating computer vision and natural language processing technologies, and implement multiple approaches based on both discriminative and generative artificial intelligence architectures. A comprehensive evaluation was conducted on a dataset created for studying combinational creativity. Among the implementations of the proposed algorithm, the most effective approach demonstrated a high accuracy in interpretation, achieving 87.5% for identifying 'base' and 80% for 'additive'. We conduct a modular analysis and an ablation experiment to assess the performance of each part in our implementations. Additionally, the study includes an analysis of error cases and bottleneck issues, providing critical insights into the limitations and challenges inherent in the computational interpretation of creative designs.
ChatScratch: An AI-Augmented System Toward Autonomous Visual Programming Learning for Children Aged 6-12
Feb 07, 2024As Computational Thinking (CT) continues to permeate younger age groups in K-12 education, established CT platforms such as Scratch face challenges in catering to these younger learners, particularly those in the elementary school (ages 6-12). Through formative investigation with Scratch experts, we uncover three key obstacles to children's autonomous Scratch learning: artist's block in project planning, bounded creativity in asset creation, and inadequate coding guidance during implementation. To address these barriers, we introduce ChatScratch, an AI-augmented system to facilitate autonomous programming learning for young children. ChatScratch employs structured interactive storyboards and visual cues to overcome artist's block, integrates digital drawing and advanced image generation technologies to elevate creativity, and leverages Scratch-specialized Large Language Models (LLMs) for professional coding guidance. Our study shows that, compared to Scratch, ChatScratch efficiently fosters autonomous programming learning, and contributes to the creation of high-quality, personally meaningful Scratch projects for children.
EGFE: End-to-end Grouping of Fragmented Elements in UI Designs with Multimodal Learning
Sep 18, 2023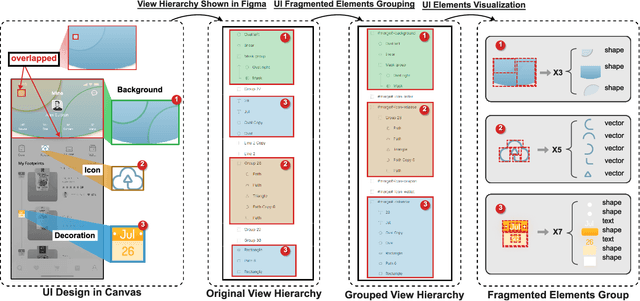
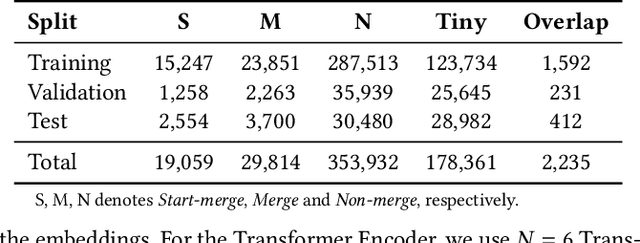
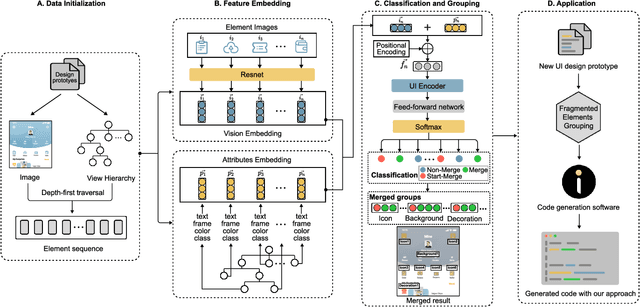
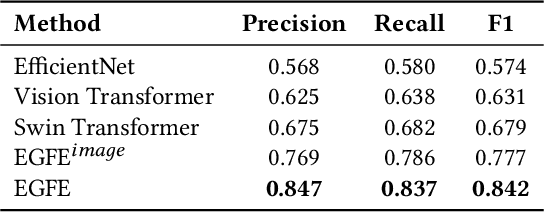
When translating UI design prototypes to code in industry, automatically generating code from design prototypes can expedite the development of applications and GUI iterations. However, in design prototypes without strict design specifications, UI components may be composed of fragmented elements. Grouping these fragmented elements can greatly improve the readability and maintainability of the generated code. Current methods employ a two-stage strategy that introduces hand-crafted rules to group fragmented elements. Unfortunately, the performance of these methods is not satisfying due to visually overlapped and tiny UI elements. In this study, we propose EGFE, a novel method for automatically End-to-end Grouping Fragmented Elements via UI sequence prediction. To facilitate the UI understanding, we innovatively construct a Transformer encoder to model the relationship between the UI elements with multi-modal representation learning. The evaluation on a dataset of 4606 UI prototypes collected from professional UI designers shows that our method outperforms the state-of-the-art baselines in the precision (by 29.75\%), recall (by 31.07\%), and F1-score (by 30.39\%) at edit distance threshold of 4. In addition, we conduct an empirical study to assess the improvement of the generated front-end code. The results demonstrate the effectiveness of our method on a real software engineering application. Our end-to-end fragmented elements grouping method creates opportunities for improving UI-related software engineering tasks.
UI Layers Group Detector: Grouping UI Layers via Text Fusion and Box Attention
Dec 07, 2022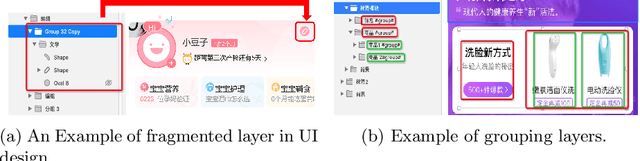
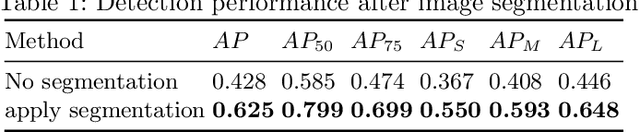

Graphic User Interface (GUI) is facing great demand with the popularization and prosperity of mobile apps. Automatic UI code generation from UI design draft dramatically simplifies the development process. However, the nesting layer structure in the design draft affects the quality and usability of the generated code. Few existing GUI automated techniques detect and group the nested layers to improve the accessibility of generated code. In this paper, we proposed our UI Layers Group Detector as a vision-based method that automatically detects images (i.e., basic shapes and visual elements) and text layers that present the same semantic meanings. We propose two plug-in components, text fusion and box attention, that utilize text information from design drafts as a priori information for group localization. We construct a large-scale UI dataset for training and testing, and present a data augmentation approach to boost the detection performance. The experiment shows that the proposed method achieves a decent accuracy regarding layers grouping.
ULDGNN: A Fragmented UI Layer Detector Based on Graph Neural Networks
Aug 13, 2022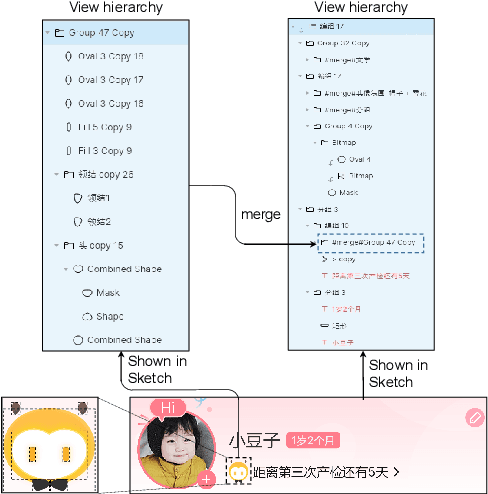
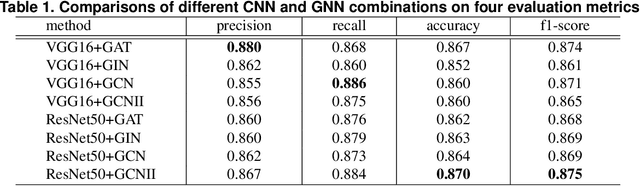
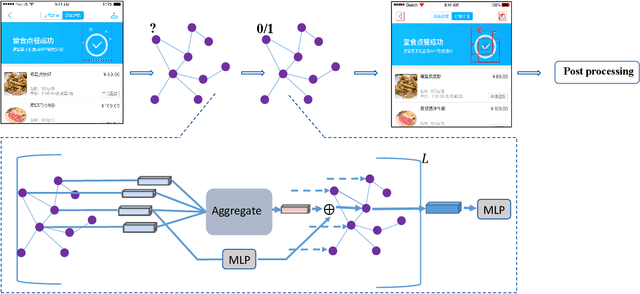

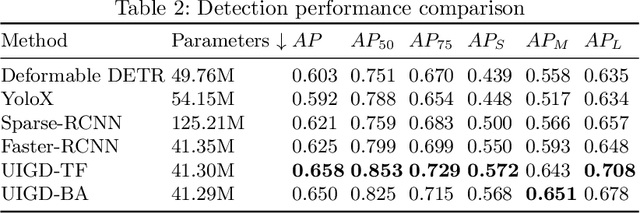
While some work attempt to generate front-end code intelligently from UI screenshots, it may be more convenient to utilize UI design drafts in Sketch which is a popular UI design software, because we can access multimodal UI information directly such as layers type, position, size, and visual images. However, fragmented layers could degrade the code quality without being merged into a whole part if all of them are involved in the code generation. In this paper, we propose a pipeline to merge fragmented layers automatically. We first construct a graph representation for the layer tree of a UI draft and detect all fragmented layers based on the visual features and graph neural networks. Then a rule-based algorithm is designed to merge fragmented layers. Through experiments on a newly constructed dataset, our approach can retrieve most fragmented layers in UI design drafts, and achieve 87% accuracy in the detection task, and the post-processing algorithm is developed to cluster associative layers under simple and general circumstances.