 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCell as Point: One-Stage Framework for Efficient Cell Tracking
Nov 22, 2024



Cellular activities are dynamic and intricate, playing a crucial role in advancing diagnostic and therapeutic techniques, yet they often require substantial resources for accurate tracking. Despite recent progress, the conventional multi-stage cell tracking approaches not only heavily rely on detection or segmentation results as a prerequisite for the tracking stage, demanding plenty of refined segmentation masks, but are also deteriorated by imbalanced and long sequence data, leading to under-learning in training and missing cells in inference procedures. To alleviate the above issues, this paper proposes the novel end-to-end CAP framework, which leverages the idea of regarding Cell as Point to achieve efficient and stable cell tracking in one stage. CAP abandons detection or segmentation stages and simplifies the process by exploiting the correlation among the trajectories of cell points to track cells jointly, thus reducing the label demand and complexity of the pipeline. With cell point trajectory and visibility to represent cell locations and lineage relationships, CAP leverages the key innovations of adaptive event-guided (AEG) sampling for addressing data imbalance in cell division events and the rolling-as-window (RAW) inference method to ensure continuous tracking of new cells in the long term. Eliminating the need for a prerequisite detection or segmentation stage, CAP demonstrates strong cell tracking performance while also being 10 to 55 times more efficient than existing methods. The code and models will be released.
Multi-source-free Domain Adaptation via Uncertainty-aware Adaptive Distillation
Feb 09, 2024

Source-free domain adaptation (SFDA) alleviates the domain discrepancy among data obtained from domains without accessing the data for the awareness of data privacy. However, existing conventional SFDA methods face inherent limitations in medical contexts, where medical data are typically collected from multiple institutions using various equipment. To address this problem, we propose a simple yet effective method, named Uncertainty-aware Adaptive Distillation (UAD) for the multi-source-free unsupervised domain adaptation (MSFDA) setting. UAD aims to perform well-calibrated knowledge distillation from (i) model level to deliver coordinated and reliable base model initialisation and (ii) instance level via model adaptation guided by high-quality pseudo-labels, thereby obtaining a high-performance target domain model. To verify its general applicability, we evaluate UAD on two image-based diagnosis benchmarks among two multi-centre datasets, where our method shows a significant performance gain compared with existing works. The code will be available soon.
ChatScratch: An AI-Augmented System Toward Autonomous Visual Programming Learning for Children Aged 6-12
Feb 07, 2024As Computational Thinking (CT) continues to permeate younger age groups in K-12 education, established CT platforms such as Scratch face challenges in catering to these younger learners, particularly those in the elementary school (ages 6-12). Through formative investigation with Scratch experts, we uncover three key obstacles to children's autonomous Scratch learning: artist's block in project planning, bounded creativity in asset creation, and inadequate coding guidance during implementation. To address these barriers, we introduce ChatScratch, an AI-augmented system to facilitate autonomous programming learning for young children. ChatScratch employs structured interactive storyboards and visual cues to overcome artist's block, integrates digital drawing and advanced image generation technologies to elevate creativity, and leverages Scratch-specialized Large Language Models (LLMs) for professional coding guidance. Our study shows that, compared to Scratch, ChatScratch efficiently fosters autonomous programming learning, and contributes to the creation of high-quality, personally meaningful Scratch projects for children.
EGFE: End-to-end Grouping of Fragmented Elements in UI Designs with Multimodal Learning
Sep 18, 2023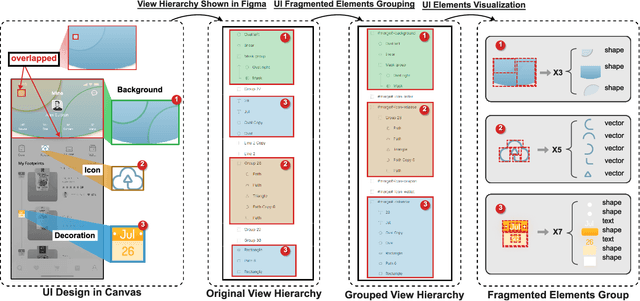
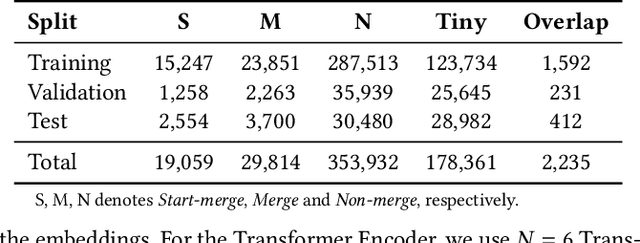
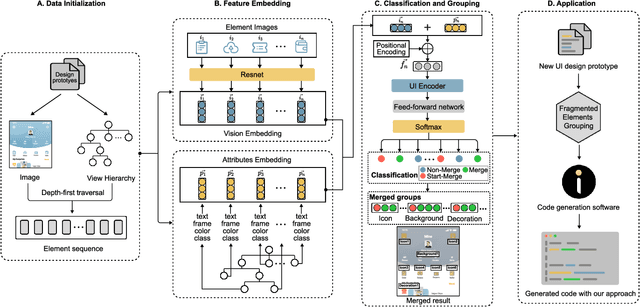
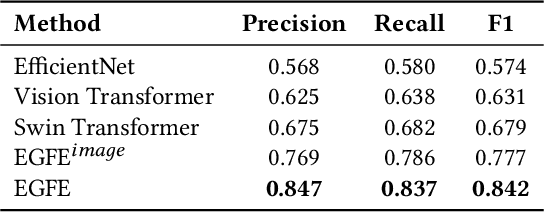
When translating UI design prototypes to code in industry, automatically generating code from design prototypes can expedite the development of applications and GUI iterations. However, in design prototypes without strict design specifications, UI components may be composed of fragmented elements. Grouping these fragmented elements can greatly improve the readability and maintainability of the generated code. Current methods employ a two-stage strategy that introduces hand-crafted rules to group fragmented elements. Unfortunately, the performance of these methods is not satisfying due to visually overlapped and tiny UI elements. In this study, we propose EGFE, a novel method for automatically End-to-end Grouping Fragmented Elements via UI sequence prediction. To facilitate the UI understanding, we innovatively construct a Transformer encoder to model the relationship between the UI elements with multi-modal representation learning. The evaluation on a dataset of 4606 UI prototypes collected from professional UI designers shows that our method outperforms the state-of-the-art baselines in the precision (by 29.75\%), recall (by 31.07\%), and F1-score (by 30.39\%) at edit distance threshold of 4. In addition, we conduct an empirical study to assess the improvement of the generated front-end code. The results demonstrate the effectiveness of our method on a real software engineering application. Our end-to-end fragmented elements grouping method creates opportunities for improving UI-related software engineering tasks.