 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Scaling Laws in Deep Neural Networks via Feature Learning Dynamics
Dec 24, 2025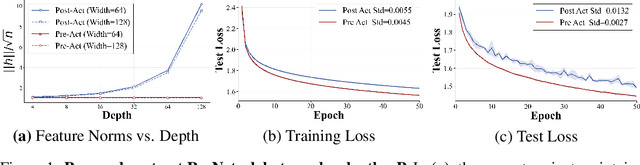


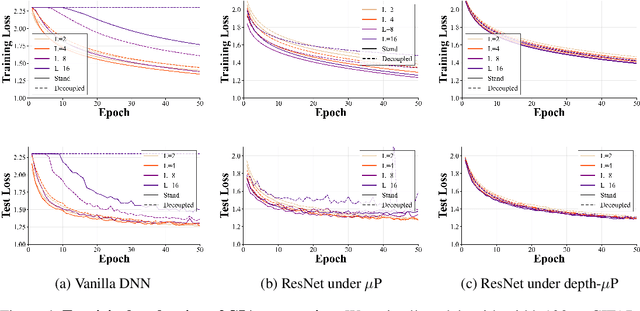
The empirical success of deep learning is often attributed to scaling laws that predict consistent gains as model, data, and compute grow; however, large models can exhibit training instability and diminishing returns, suggesting that scaling laws describe what success looks like but not when and why scaling succeeds or fails. A central obstacle is the lack of a rigorous understanding of feature learning at large depth. While muP characterizes feature-learning dynamics in the infinite-width limit and enables hyperparameter transfer across width, its depth extension (depth-muP) breaks down for residual blocks with more than one internal layer. We derive Neural Feature Dynamics (NFD) for ResNets with single-layer residual blocks, characterizing feature learning via a coupled forward-backward stochastic system in the joint infinite-width and infinite-depth limit. In this regime, NFD identifies when scaling-law trends persist and explains diminishing returns. It also reveals a vanishing mechanism induced by the 1/sqrt(depth) residual scaling under which the gradient-independence assumption (GIA), known to fail during training at finite depth, becomes provably valid again at infinite depth, yielding an analytically tractable regime for end-to-end feature learning. Motivated by this insight, we study two-layer residual blocks and show that the same mechanism causes feature-learning collapse in the first internal layer at large depth, providing a structural explanation for the empirical failure of depth-muP. Based on this diagnosis, we propose a depth-aware learning-rate correction that counteracts the collapse and empirically restores depth-wise hyperparameter transfer, yielding stronger performance in deeper ResNets.
Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
Dec 30, 2024



Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success. As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context. This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP. The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence. An associated GitHub repository collecting the latest papers and repos is available at https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction
ChatScratch: An AI-Augmented System Toward Autonomous Visual Programming Learning for Children Aged 6-12
Feb 07, 2024As Computational Thinking (CT) continues to permeate younger age groups in K-12 education, established CT platforms such as Scratch face challenges in catering to these younger learners, particularly those in the elementary school (ages 6-12). Through formative investigation with Scratch experts, we uncover three key obstacles to children's autonomous Scratch learning: artist's block in project planning, bounded creativity in asset creation, and inadequate coding guidance during implementation. To address these barriers, we introduce ChatScratch, an AI-augmented system to facilitate autonomous programming learning for young children. ChatScratch employs structured interactive storyboards and visual cues to overcome artist's block, integrates digital drawing and advanced image generation technologies to elevate creativity, and leverages Scratch-specialized Large Language Models (LLMs) for professional coding guidance. Our study shows that, compared to Scratch, ChatScratch efficiently fosters autonomous programming learning, and contributes to the creation of high-quality, personally meaningful Scratch projects for children.