 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Hear by Seeing: It's Time for Vision Language Models to Understand Artistic Emotion from Sight and Sound
Nov 15, 2025Emotion understanding is critical for making Large Language Models (LLMs) more general, reliable, and aligned with humans. Art conveys emotion through the joint design of visual and auditory elements, yet most prior work is human-centered or single-modality, overlooking the emotion intentionally expressed by the artwork. Meanwhile, current Audio-Visual Language Models (AVLMs) typically require large-scale audio pretraining to endow Visual Language Models (VLMs) with hearing, which limits scalability. We present Vision Anchored Audio-Visual Emotion LLM (VAEmotionLLM), a two-stage framework that teaches a VLM to hear by seeing with limited audio pretraining and to understand emotion across modalities. In Stage 1, Vision-Guided Audio Alignment (VG-Align) distills the frozen visual pathway into a new audio pathway by aligning next-token distributions of the shared LLM on synchronized audio-video clips, enabling hearing without a large audio dataset. In Stage 2, a lightweight Cross-Modal Emotion Adapter (EmoAdapter), composed of the Emotion Enhancer and the Emotion Supervisor, injects emotion-sensitive residuals and applies emotion supervision to enhance cross-modal emotion understanding. We also construct ArtEmoBenchmark, an art-centric emotion benchmark that evaluates content and emotion understanding under audio-only, visual-only, and audio-visual inputs. VAEmotionLLM achieves state-of-the-art results on ArtEmoBenchmark, outperforming audio-only, visual-only, and audio-visual baselines. Ablations show that the proposed components are complementary.
Controllable Video-to-Music Generation with Multiple Time-Varying Conditions
Jul 28, 2025Music enhances video narratives and emotions, driving demand for automatic video-to-music (V2M) generation. However, existing V2M methods relying solely on visual features or supplementary textual inputs generate music in a black-box manner, often failing to meet user expectations. To address this challenge, we propose a novel multi-condition guided V2M generation framework that incorporates multiple time-varying conditions for enhanced control over music generation. Our method uses a two-stage training strategy that enables learning of V2M fundamentals and audiovisual temporal synchronization while meeting users' needs for multi-condition control. In the first stage, we introduce a fine-grained feature selection module and a progressive temporal alignment attention mechanism to ensure flexible feature alignment. For the second stage, we develop a dynamic conditional fusion module and a control-guided decoder module to integrate multiple conditions and accurately guide the music composition process. Extensive experiments demonstrate that our method outperforms existing V2M pipelines in both subjective and objective evaluations, significantly enhancing control and alignment with user expectations.
GVMGen: A General Video-to-Music Generation Model with Hierarchical Attentions
Jan 17, 2025Composing music for video is essential yet challenging, leading to a growing interest in automating music generation for video applications. Existing approaches often struggle to achieve robust music-video correspondence and generative diversity, primarily due to inadequate feature alignment methods and insufficient datasets. In this study, we present General Video-to-Music Generation model (GVMGen), designed for generating high-related music to the video input. Our model employs hierarchical attentions to extract and align video features with music in both spatial and temporal dimensions, ensuring the preservation of pertinent features while minimizing redundancy. Remarkably, our method is versatile, capable of generating multi-style music from different video inputs, even in zero-shot scenarios. We also propose an evaluation model along with two novel objective metrics for assessing video-music alignment. Additionally, we have compiled a large-scale dataset comprising diverse types of video-music pairs. Experimental results demonstrate that GVMGen surpasses previous models in terms of music-video correspondence, generative diversity, and application universality.
Personalized Dynamic Music Emotion Recognition with Dual-Scale Attention-Based Meta-Learning
Dec 26, 2024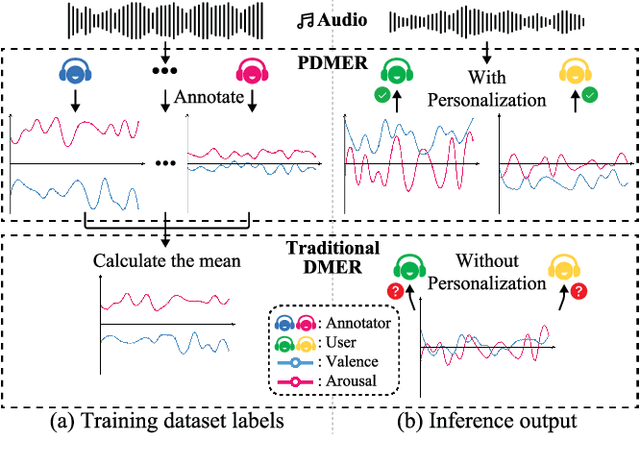
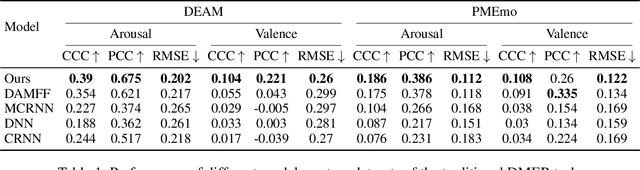
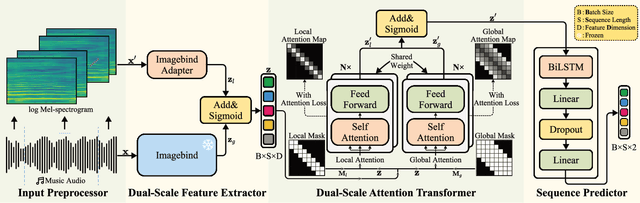
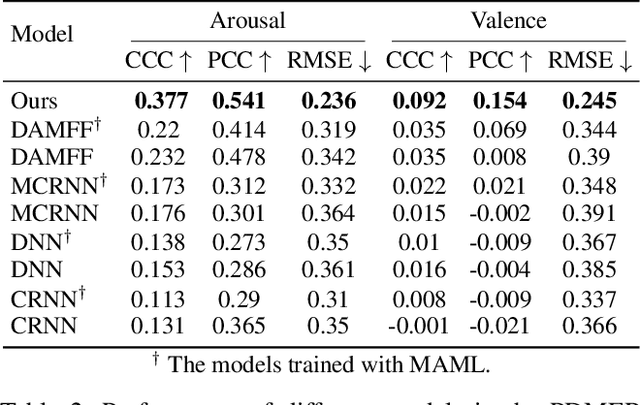
Dynamic Music Emotion Recognition (DMER) aims to predict the emotion of different moments in music, playing a crucial role in music information retrieval. The existing DMER methods struggle to capture long-term dependencies when dealing with sequence data, which limits their performance. Furthermore, these methods often overlook the influence of individual differences on emotion perception, even though everyone has their own personalized emotional perception in the real world. Motivated by these issues, we explore more effective sequence processing methods and introduce the Personalized DMER (PDMER) problem, which requires models to predict emotions that align with personalized perception. Specifically, we propose a Dual-Scale Attention-Based Meta-Learning (DSAML) method. This method fuses features from a dual-scale feature extractor and captures both short and long-term dependencies using a dual-scale attention transformer, improving the performance in traditional DMER. To achieve PDMER, we design a novel task construction strategy that divides tasks by annotators. Samples in a task are annotated by the same annotator, ensuring consistent perception. Leveraging this strategy alongside meta-learning, DSAML can predict personalized perception of emotions with just one personalized annotation sample. Our objective and subjective experiments demonstrate that our method can achieve state-of-the-art performance in both traditional DMER and PDMER.
Efficient and Scalable Chinese Vector Font Generation via Component Composition
Apr 10, 2024



Chinese vector font generation is challenging due to the complex structure and huge amount of Chinese characters. Recent advances remain limited to generating a small set of characters with simple structure. In this work, we first observe that most Chinese characters can be disassembled into frequently-reused components. Therefore, we introduce the first efficient and scalable Chinese vector font generation approach via component composition, allowing generating numerous vector characters from a small set of components. To achieve this, we collect a large-scale dataset that contains over \textit{90K} Chinese characters with their components and layout information. Upon the dataset, we propose a simple yet effective framework based on spatial transformer networks (STN) and multiple losses tailored to font characteristics to learn the affine transformation of the components, which can be directly applied to the B\'ezier curves, resulting in Chinese characters in vector format. Our qualitative and quantitative experiments have demonstrated that our method significantly surpasses the state-of-the-art vector font generation methods in generating large-scale complex Chinese characters in both font generation and zero-shot font extension.