 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Scalable Chinese Vector Font Generation via Component Composition
Apr 10, 2024



Chinese vector font generation is challenging due to the complex structure and huge amount of Chinese characters. Recent advances remain limited to generating a small set of characters with simple structure. In this work, we first observe that most Chinese characters can be disassembled into frequently-reused components. Therefore, we introduce the first efficient and scalable Chinese vector font generation approach via component composition, allowing generating numerous vector characters from a small set of components. To achieve this, we collect a large-scale dataset that contains over \textit{90K} Chinese characters with their components and layout information. Upon the dataset, we propose a simple yet effective framework based on spatial transformer networks (STN) and multiple losses tailored to font characteristics to learn the affine transformation of the components, which can be directly applied to the B\'ezier curves, resulting in Chinese characters in vector format. Our qualitative and quantitative experiments have demonstrated that our method significantly surpasses the state-of-the-art vector font generation methods in generating large-scale complex Chinese characters in both font generation and zero-shot font extension.
$α$ DARTS Once More: Enhancing Differentiable Architecture Search by Masked Image Modeling
Nov 18, 2022Differentiable architecture search (DARTS) has been a mainstream direction in automatic machine learning. Since the discovery that original DARTS will inevitably converge to poor architectures, recent works alleviate this by either designing rule-based architecture selection techniques or incorporating complex regularization techniques, abandoning the simplicity of the original DARTS that selects architectures based on the largest parametric value, namely $\alpha$. Moreover, we find that all the previous attempts only rely on classification labels, hence learning only single modal information and limiting the representation power of the shared network. To this end, we propose to additionally inject semantic information by formulating a patch recovery approach. Specifically, we exploit the recent trending masked image modeling and do not abandon the guidance from the downstream tasks during the search phase. Our method surpasses all previous DARTS variants and achieves state-of-the-art results on CIFAR-10, CIFAR-100, and ImageNet without complex manual-designed strategies.
Knowledge Distillation for 6D Pose Estimation by Keypoint Distribution Alignment
May 30, 2022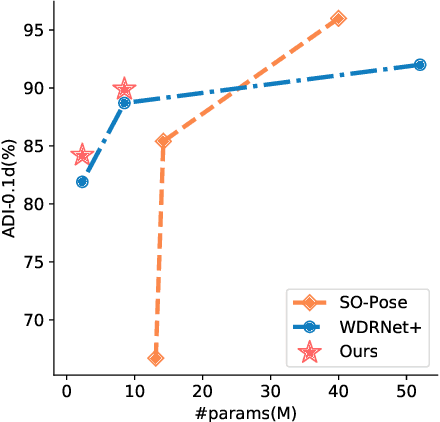
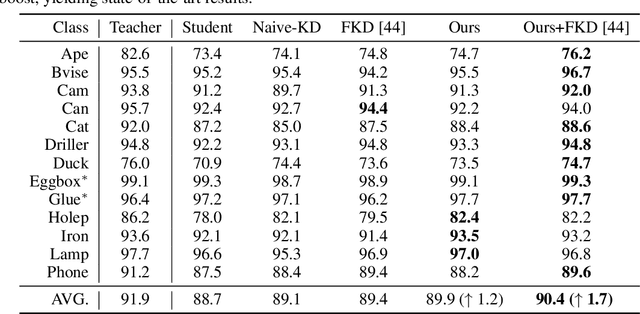

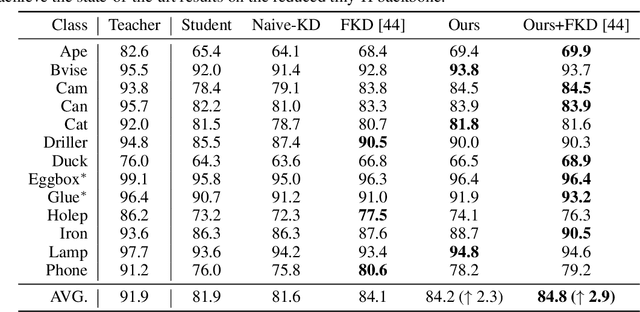
Knowledge distillation facilitates the training of a compact student network by using a deep teacher one. While this has achieved great success in many tasks, it remains completely unstudied for image-based 6D object pose estimation. In this work, we introduce the first knowledge distillation method for 6D pose estimation. Specifically, we follow a standard approach to 6D pose estimation, consisting of predicting the 2D image locations of object keypoints. In this context, we observe the compact student network to struggle predicting precise 2D keypoint locations. Therefore, to address this, instead of training the student with keypoint-to-keypoint supervision, we introduce a strategy based the optimal transport theory that distills the teacher's keypoint \emph{distribution} into the student network, facilitating its training. Our experiments on several benchmarks show that our distillation method yields state-of-the-art results with different compact student models.
Distilling Image Classifiers in Object Detectors
Jun 09, 2021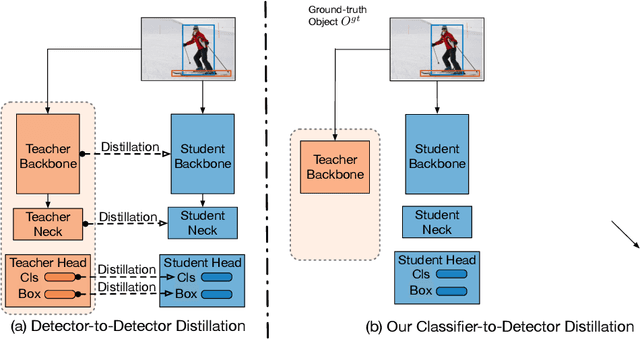
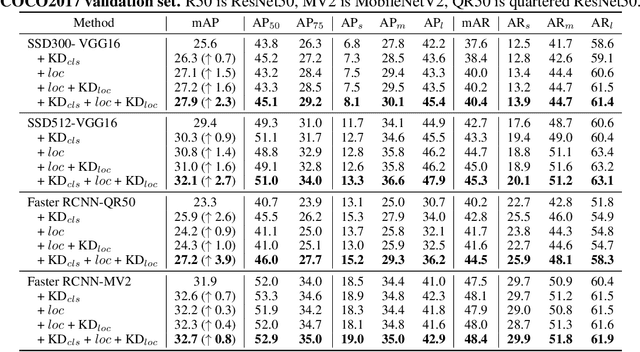
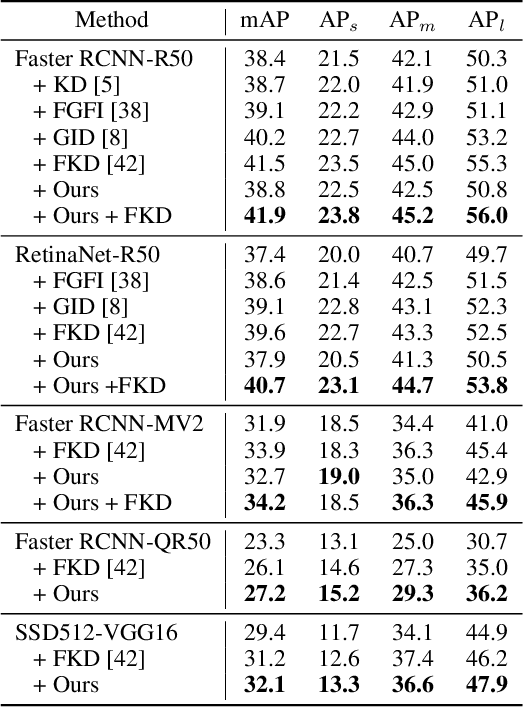

Knowledge distillation constitutes a simple yet effective way to improve the performance of a compact student network by exploiting the knowledge of a more powerful teacher. Nevertheless, the knowledge distillation literature remains limited to the scenario where the student and the teacher tackle the same task. Here, we investigate the problem of transferring knowledge not only across architectures but also across tasks. To this end, we study the case of object detection and, instead of following the standard detector-to-detector distillation approach, introduce a classifier-to-detector knowledge transfer framework. In particular, we propose strategies to exploit the classification teacher to improve both the detector's recognition accuracy and localization performance. Our experiments on several detectors with different backbones demonstrate the effectiveness of our approach, allowing us to outperform the state-of-the-art detector-to-detector distillation methods.
ExpandNets: Exploiting Linear Redundancy to Train Small Networks
Dec 12, 2018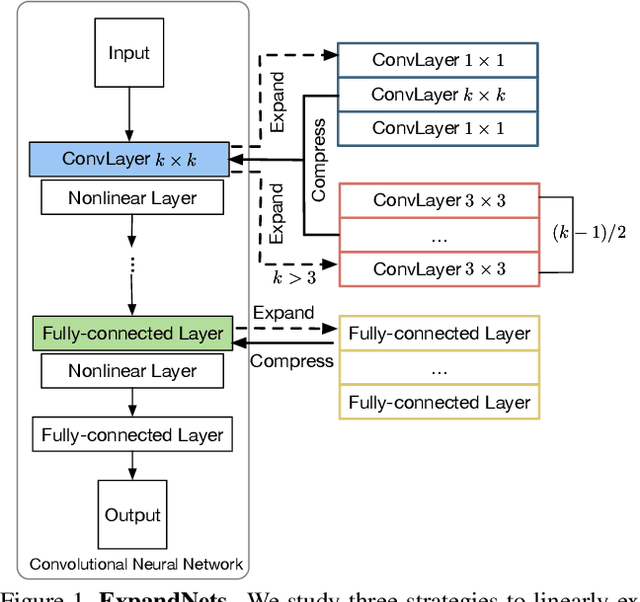

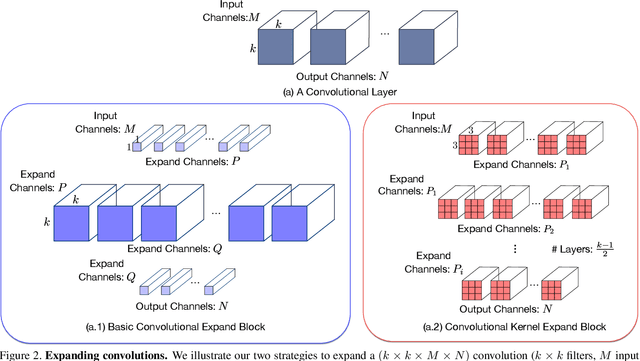

While very deep networks can achieve great performance, they are ill-suited to applications in resource-constrained environments. Knowledge transfer, which leverages a deep teacher network to train a given small network, has emerged as one of the most popular strategies to address this problem. In this paper, we introduce an alternative approach to training a given small network, based on the intuition that parameter redundancy facilitates learning. We propose to expand each linear layer of a small network into multiple linear layers, without adding any nonlinearity. As such, the resulting expanded network can be compressed back to the small one algebraically, but, as evidenced by our experiments, consistently outperforms training the small network from scratch. This strategy is orthogonal to knowledge transfer. We therefore further show on several standard benchmarks that, for any knowledge transfer technique, using our expanded network as student systematically improves over using the small network.