 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpandNets: Exploiting Linear Redundancy to Train Small Networks
Paper and Code
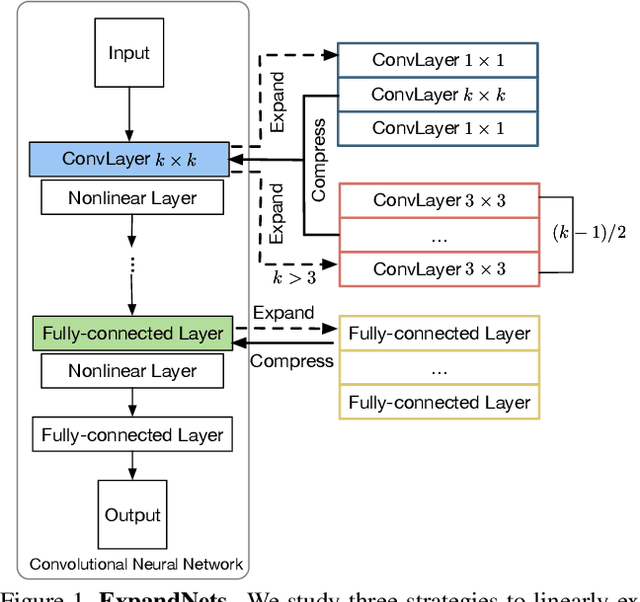

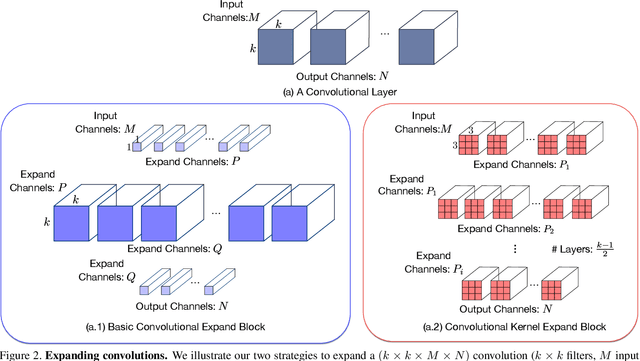

While very deep networks can achieve great performance, they are ill-suited to applications in resource-constrained environments. Knowledge transfer, which leverages a deep teacher network to train a given small network, has emerged as one of the most popular strategies to address this problem. In this paper, we introduce an alternative approach to training a given small network, based on the intuition that parameter redundancy facilitates learning. We propose to expand each linear layer of a small network into multiple linear layers, without adding any nonlinearity. As such, the resulting expanded network can be compressed back to the small one algebraically, but, as evidenced by our experiments, consistently outperforms training the small network from scratch. This strategy is orthogonal to knowledge transfer. We therefore further show on several standard benchmarks that, for any knowledge transfer technique, using our expanded network as student systematically improves over using the small network.