 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$α$ DARTS Once More: Enhancing Differentiable Architecture Search by Masked Image Modeling
Nov 18, 2022Differentiable architecture search (DARTS) has been a mainstream direction in automatic machine learning. Since the discovery that original DARTS will inevitably converge to poor architectures, recent works alleviate this by either designing rule-based architecture selection techniques or incorporating complex regularization techniques, abandoning the simplicity of the original DARTS that selects architectures based on the largest parametric value, namely $\alpha$. Moreover, we find that all the previous attempts only rely on classification labels, hence learning only single modal information and limiting the representation power of the shared network. To this end, we propose to additionally inject semantic information by formulating a patch recovery approach. Specifically, we exploit the recent trending masked image modeling and do not abandon the guidance from the downstream tasks during the search phase. Our method surpasses all previous DARTS variants and achieves state-of-the-art results on CIFAR-10, CIFAR-100, and ImageNet without complex manual-designed strategies.
Neural Architecture Ranker
Jan 30, 2022


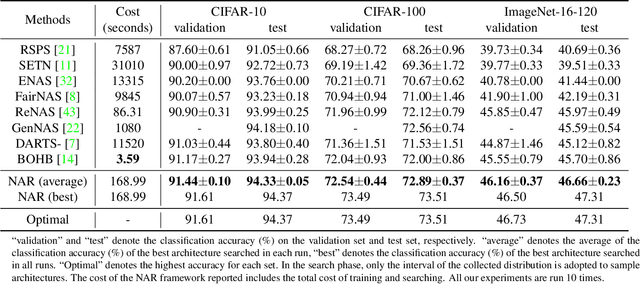
Architecture ranking has recently been advocated to design an efficient and effective performance predictor for Neural Architecture Search (NAS). The previous contrastive method solves the ranking problem by comparing pairs of architectures and predicting their relative performance, which may suffer generalization issues due to local pair-wise comparison. Inspired by the quality stratification phenomenon in the search space, we propose a predictor, namely Neural Architecture Ranker (NAR), from a new and global perspective by exploiting the quality distribution of the whole search space. The NAR learns the similar characteristics of the same quality tier (i.e., level) and distinguishes among different individuals by first matching architectures with the representation of tiers, and then classifying and scoring them. It can capture the features of different quality tiers and thus generalize its ranking ability to the entire search space. Besides, distributions of different quality tiers are also beneficial to guide the sampling procedure, which is free of training a search algorithm and thus simplifies the NAS pipeline. The proposed NAR achieves better performance than the state-of-the-art methods on two widely accepted datasets. On NAS-Bench-101, it finds the architectures with top 0.01$\unicode{x2030}$ performance among the search space and stably focuses on the top architectures. On NAS-Bench-201, it identifies the optimal architectures on CIFAR-10, CIFAR-100 and, ImageNet-16-120. We expand and release these two datasets covering detailed cell computational information to boost the study of NAS.