 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-center analysis of deep learning methods for video polyp detection and segmentation
Mar 04, 2026Colonic polyps are well-recognized precursors to colorectal cancer (CRC), typically detected during colonoscopy. However, the variability in appearance, location, and size of these polyps complicates their detection and removal, leading to challenges in effective surveillance, intervention, and subsequently CRC prevention. The processes of colonoscopy surveillance and polyp removal are highly reliant on the expertise of gastroenterologists and occur within the complexities of the colonic structure. As a result, there is a high rate of missed detections and incomplete removal of colonic polyps, which can adversely impact patient outcomes. Recently, automated methods that use machine learning have been developed to enhance polyps detection and segmentation, thus helping clinical processes and reducing missed rates. These advancements highlight the potential for improving diagnostic accuracy in real-time applications, which ultimately facilitates more effective patient management. Furthermore, integrating sequence data and temporal information could significantly enhance the precision of these methods by capturing the dynamic nature of polyp growth and the changes that occur over time. To rigorously investigate these challenges, data scientists and experts gastroenterologists collaborated to compile a comprehensive dataset that spans multiple centers and diverse populations. This initiative aims to underscore the critical importance of incorporating sequence data and temporal information in the development of robust automated detection and segmentation methods. This study evaluates the applicability of deep learning techniques developed in real-time clinical colonoscopy tasks using sequence data, highlighting the critical role of temporal relationships between frames in improving diagnostic precision.
Adaptive Wavelet Filters as Practical Texture Feature Amplifiers for Parkinson's Disease Screening in OCT
Mar 25, 2025Parkinson's disease (PD) is a prevalent neurodegenerative disorder globally. The eye's retina is an extension of the brain and has great potential in PD screening. Recent studies have suggested that texture features extracted from retinal layers can be adopted as biomarkers for PD diagnosis under optical coherence tomography (OCT) images. Frequency domain learning techniques can enhance the feature representations of deep neural networks (DNNs) by decomposing frequency components involving rich texture features. Additionally, previous works have not exploited texture features for automated PD screening in OCT. Motivated by the above analysis, we propose a novel Adaptive Wavelet Filter (AWF) that serves as the Practical Texture Feature Amplifier to fully leverage the merits of texture features to boost the PD screening performance of DNNs with the aid of frequency domain learning. Specifically, AWF first enhances texture feature representation diversities via channel mixer, then emphasizes informative texture feature representations with the well-designed adaptive wavelet filtering token mixer. By combining the AWFs with the DNN stem, AWFNet is constructed for automated PD screening. Additionally, we introduce a novel Balanced Confidence (BC) Loss by mining the potential of sample-wise predicted probabilities of all classes and class frequency prior, to further boost the PD screening performance and trustworthiness of AWFNet. The extensive experiments manifest the superiority of our AWFNet and BC over state-of-the-art methods in terms of PD screening performance and trustworthiness.
EEG-GMACN: Interpretable EEG Graph Mutual Attention Convolutional Network
Dec 15, 2024



Electroencephalogram (EEG) is a valuable technique to record brain electrical activity through electrodes placed on the scalp. Analyzing EEG signals contributes to the understanding of neurological conditions and developing brain-computer interface. Graph Signal Processing (GSP) has emerged as a promising method for EEG spatial-temporal analysis, by further considering the topological relationships between electrodes. However, existing GSP studies lack interpretability of electrode importance and the credibility of prediction confidence. This work proposes an EEG Graph Mutual Attention Convolutional Network (EEG-GMACN), by introducing an 'Inverse Graph Weight Module' to output interpretable electrode graph weights, enhancing the clinical credibility and interpretability of EEG classification results. Additionally, we incorporate a mutual attention mechanism module into the model to improve its capability to distinguish critical electrodes and introduce credibility calibration to assess the uncertainty of prediction results. This study enhances the transparency and effectiveness of EEG analysis, paving the way for its widespread use in clinical and neuroscience research.
VSR-Net: Vessel-like Structure Rehabilitation Network with Graph Clustering
Dec 20, 2023



The morphologies of vessel-like structures, such as blood vessels and nerve fibres, play significant roles in disease diagnosis, e.g., Parkinson's disease. Deep network-based refinement segmentation methods have recently achieved promising vessel-like structure segmentation results. There are still two challenges: (1) existing methods have limitations in rehabilitating subsection ruptures in segmented vessel-like structures; (2) they are often overconfident in predicted segmentation results. To tackle these two challenges, this paper attempts to leverage the potential of spatial interconnection relationships among subsection ruptures from the structure rehabilitation perspective. Based on this, we propose a novel Vessel-like Structure Rehabilitation Network (VSR-Net) to rehabilitate subsection ruptures and improve the model calibration based on coarse vessel-like structure segmentation results. VSR-Net first constructs subsection rupture clusters with Curvilinear Clustering Module (CCM). Then, the well-designed Curvilinear Merging Module (CMM) is applied to rehabilitate the subsection ruptures to obtain the refined vessel-like structures. Extensive experiments on five 2D/3D medical image datasets show that VSR-Net significantly outperforms state-of-the-art (SOTA) refinement segmentation methods with lower calibration error. Additionally, we provide quantitative analysis to explain the morphological difference between the rehabilitation results of VSR-Net and ground truth (GT), which is smaller than SOTA methods and GT, demonstrating that our method better rehabilitates vessel-like structures by restoring subsection ruptures.
2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021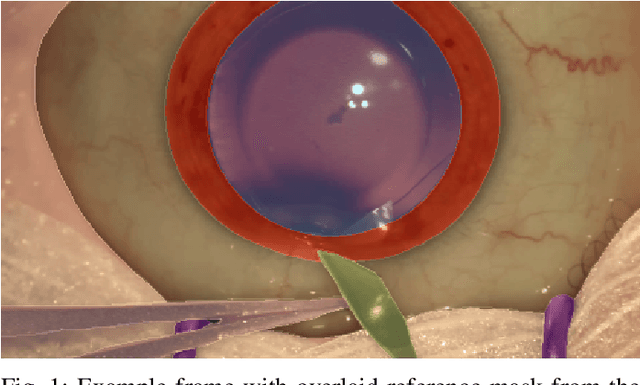
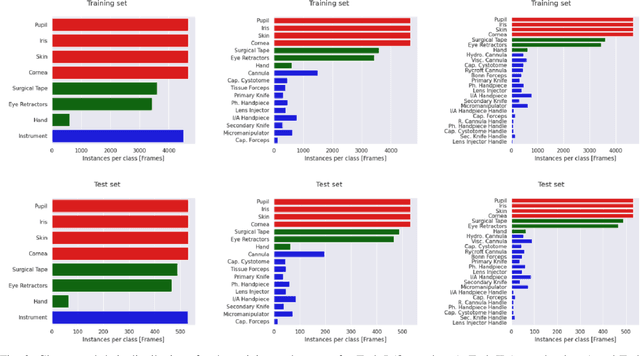
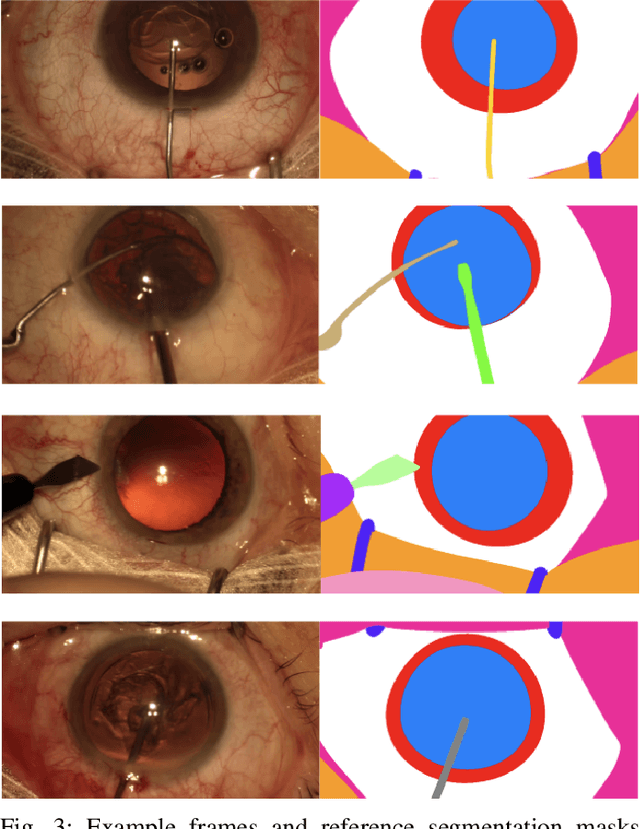
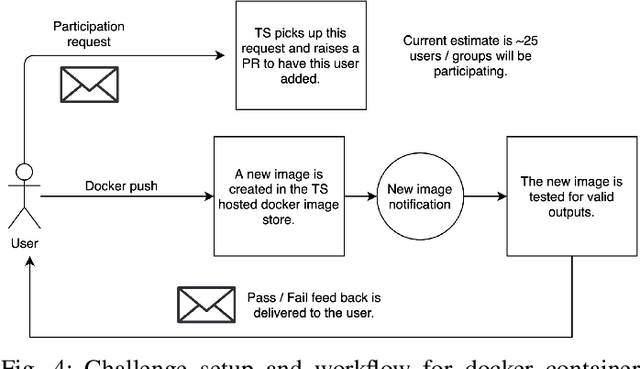
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.