 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnim-Director: A Large Multimodal Model Powered Agent for Controllable Animation Video Generation
Aug 19, 2024
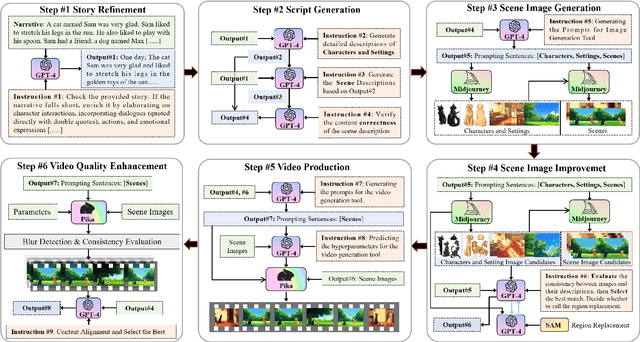

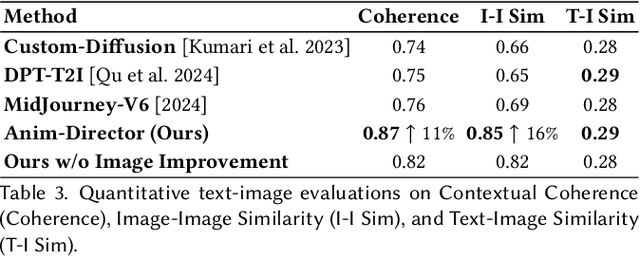
Traditional animation generation methods depend on training generative models with human-labelled data, entailing a sophisticated multi-stage pipeline that demands substantial human effort and incurs high training costs. Due to limited prompting plans, these methods typically produce brief, information-poor, and context-incoherent animations. To overcome these limitations and automate the animation process, we pioneer the introduction of large multimodal models (LMMs) as the core processor to build an autonomous animation-making agent, named Anim-Director. This agent mainly harnesses the advanced understanding and reasoning capabilities of LMMs and generative AI tools to create animated videos from concise narratives or simple instructions. Specifically, it operates in three main stages: Firstly, the Anim-Director generates a coherent storyline from user inputs, followed by a detailed director's script that encompasses settings of character profiles and interior/exterior descriptions, and context-coherent scene descriptions that include appearing characters, interiors or exteriors, and scene events. Secondly, we employ LMMs with the image generation tool to produce visual images of settings and scenes. These images are designed to maintain visual consistency across different scenes using a visual-language prompting method that combines scene descriptions and images of the appearing character and setting. Thirdly, scene images serve as the foundation for producing animated videos, with LMMs generating prompts to guide this process. The whole process is notably autonomous without manual intervention, as the LMMs interact seamlessly with generative tools to generate prompts, evaluate visual quality, and select the best one to optimize the final output.
How to characterize imprecision in multi-view clustering?
Apr 07, 2024



It is still challenging to cluster multi-view data since existing methods can only assign an object to a specific (singleton) cluster when combining different view information. As a result, it fails to characterize imprecision of objects in overlapping regions of different clusters, thus leading to a high risk of errors. In this paper, we thereby want to answer the question: how to characterize imprecision in multi-view clustering? Correspondingly, we propose a multi-view low-rank evidential c-means based on entropy constraint (MvLRECM). The proposed MvLRECM can be considered as a multi-view version of evidential c-means based on the theory of belief functions. In MvLRECM, each object is allowed to belong to different clusters with various degrees of support (masses of belief) to characterize uncertainty when decision-making. Moreover, if an object is in the overlapping region of several singleton clusters, it can be assigned to a meta-cluster, defined as the union of these singleton clusters, to characterize the local imprecision in the result. In addition, entropy-weighting and low-rank constraints are employed to reduce imprecision and improve accuracy. Compared to state-of-the-art methods, the effectiveness of MvLRECM is demonstrated based on several toy and UCI real datasets.