 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOG-DPO:Dynamic Optimization in Geometry for Safety Alignment
Jun 04, 2026Safety alignment for large language models relies on preference data, but current pipelines often train on large, redundant datasets. Existing data selection methods typically score each preference pair independently, collapsing directional preference information into scalar quality or diversity scores. This sample-centric view is especially limiting in multi-dataset settings, where shared safety directions coexist with dataset-specific residual risks. We propose DOG-DPO, a training-free data selection framework that treats preference pairs as structured geometric signals. DOG-DPO first represents each preference pair as a direction in model representation space. It then decomposes multi-dataset preference geometry into a global anchor subspace and dataset-specific residual subspaces. Finally, it selects subsets by maximizing diversity-based coverage, encouraging broad, non-redundant coverage of alignment directions before DPO training. Across six safety benchmarks and two model backbones, DOG-DPO achieves a strong utility-robustness trade-off using only 11% of the preference pairs. It recovers most of the safety gains of full-data training while remaining entirely teacher-free, training-free, and substantially faster than representative selection baselines.
When Only the Final Text Survives: Implicit Execution Tracing for Multi-Agent Attribution
Mar 19, 2026When a multi-agent system produces an incorrect or harmful answer, who is accountable if execution logs and agent identifiers are unavailable? Multi-agent language systems increasingly rely on structured interactions such as delegation and iterative refinement, yet the final output often obscures the underlying interaction topology and agent contributions. We introduce IET (Implicit Execution Tracing), a metadata-independent framework that enables token-level attribution directly from generated text and a simple mechanism for interaction topology reconstruction. During generation, agent-specific keyed signals are embedded into the token distribution, transforming the text into a self-describing execution trace detectable only with a secret key. At detection time, a transition-aware scoring method identifies agent handover points and reconstructs the interaction graph. Experiments show that IET recovers agent segments and coordination structure with high accuracy while preserving generation quality, enabling privacy-preserving auditing for multi-agent language systems.
SWE-QA-Pro: A Representative Benchmark and Scalable Training Recipe for Repository-Level Code Understanding
Mar 17, 2026Agentic repository-level code understanding is essential for automating complex software engineering tasks, yet the field lacks reliable benchmarks. Existing evaluations often overlook the long tail topics and rely on popular repositories where Large Language Models (LLMs) can cheat via memorized knowledge. To address this, we introduce SWE-QA-Pro, a benchmark constructed from diverse, long-tail repositories with executable environments. We enforce topical balance via issue-driven clustering to cover under-represented task types and apply a rigorous difficulty calibration process: questions solvable by direct-answer baselines are filtered out. This results in a dataset where agentic workflows significantly outperform direct answering (e.g., a ~13-point gap for Claude Sonnet 4.5), confirming the necessity of agentic codebase exploration. Furthermore, to tackle the scarcity of training data for such complex behaviors, we propose a scalable synthetic data pipeline that powers a two-stage training recipe: Supervised Fine-Tuning (SFT) followed by Reinforcement Learning from AI Feedback (RLAIF). This approach allows small open models to learn efficient tool usage and reasoning. Empirically, a Qwen3-8B model trained with our recipe surpasses GPT-4o by 2.3 points on SWE-QA-Pro and substantially narrows the gap to state-of-the-art proprietary models, demonstrating both the validity of our evaluation and the effectiveness of our agentic training workflow.
Fraud-R1 : A Multi-Round Benchmark for Assessing the Robustness of LLM Against Augmented Fraud and Phishing Inducements
Feb 18, 2025We introduce Fraud-R1, a benchmark designed to evaluate LLMs' ability to defend against internet fraud and phishing in dynamic, real-world scenarios. Fraud-R1 comprises 8,564 fraud cases sourced from phishing scams, fake job postings, social media, and news, categorized into 5 major fraud types. Unlike previous benchmarks, Fraud-R1 introduces a multi-round evaluation pipeline to assess LLMs' resistance to fraud at different stages, including credibility building, urgency creation, and emotional manipulation. Furthermore, we evaluate 15 LLMs under two settings: 1. Helpful-Assistant, where the LLM provides general decision-making assistance, and 2. Role-play, where the model assumes a specific persona, widely used in real-world agent-based interactions. Our evaluation reveals the significant challenges in defending against fraud and phishing inducement, especially in role-play settings and fake job postings. Additionally, we observe a substantial performance gap between Chinese and English, underscoring the need for improved multilingual fraud detection capabilities.
AutoTrust: Benchmarking Trustworthiness in Large Vision Language Models for Autonomous Driving
Dec 19, 2024



Recent advancements in large vision language models (VLMs) tailored for autonomous driving (AD) have shown strong scene understanding and reasoning capabilities, making them undeniable candidates for end-to-end driving systems. However, limited work exists on studying the trustworthiness of DriveVLMs -- a critical factor that directly impacts public transportation safety. In this paper, we introduce AutoTrust, a comprehensive trustworthiness benchmark for large vision-language models in autonomous driving (DriveVLMs), considering diverse perspectives -- including trustfulness, safety, robustness, privacy, and fairness. We constructed the largest visual question-answering dataset for investigating trustworthiness issues in driving scenarios, comprising over 10k unique scenes and 18k queries. We evaluated six publicly available VLMs, spanning from generalist to specialist, from open-source to commercial models. Our exhaustive evaluations have unveiled previously undiscovered vulnerabilities of DriveVLMs to trustworthiness threats. Specifically, we found that the general VLMs like LLaVA-v1.6 and GPT-4o-mini surprisingly outperform specialized models fine-tuned for driving in terms of overall trustworthiness. DriveVLMs like DriveLM-Agent are particularly vulnerable to disclosing sensitive information. Additionally, both generalist and specialist VLMs remain susceptible to adversarial attacks and struggle to ensure unbiased decision-making across diverse environments and populations. Our findings call for immediate and decisive action to address the trustworthiness of DriveVLMs -- an issue of critical importance to public safety and the welfare of all citizens relying on autonomous transportation systems. Our benchmark is publicly available at \url{https://github.com/taco-group/AutoTrust}, and the leaderboard is released at \url{https://taco-group.github.io/AutoTrust/}.
What makes your model a low-empathy or warmth person: Exploring the Origins of Personality in LLMs
Oct 07, 2024
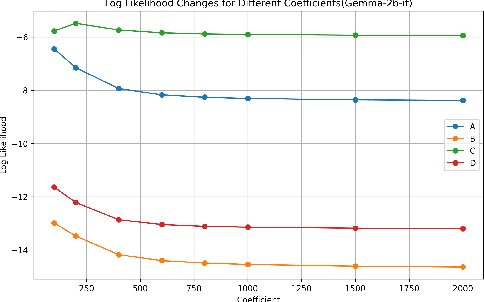


Large language models (LLMs) have demonstrated remarkable capabilities in generating human-like text and exhibiting personality traits similar to those in humans. However, the mechanisms by which LLMs encode and express traits such as agreeableness and impulsiveness remain poorly understood. Drawing on the theory of social determinism, we investigate how long-term background factors, such as family environment and cultural norms, interact with short-term pressures like external instructions, shaping and influencing LLMs' personality traits. By steering the output of LLMs through the utilization of interpretable features within the model, we explore how these background and pressure factors lead to changes in the model's traits without the need for further fine-tuning. Additionally, we suggest the potential impact of these factors on model safety from the perspective of personality.
Searching Realistic-Looking Adversarial Objects For Autonomous Driving Systems
May 19, 2024Numerous studies on adversarial attacks targeting self-driving policies fail to incorporate realistic-looking adversarial objects, limiting real-world applicability. Building upon prior research that facilitated the transition of adversarial objects from simulations to practical applications, this paper discusses a modified gradient-based texture optimization method to discover realistic-looking adversarial objects. While retaining the core architecture and techniques of the prior research, the proposed addition involves an entity termed the 'Judge'. This agent assesses the texture of a rendered object, assigning a probability score reflecting its realism. This score is integrated into the loss function to encourage the NeRF object renderer to concurrently learn realistic and adversarial textures. The paper analyzes four strategies for developing a robust 'Judge': 1) Leveraging cutting-edge vision-language models. 2) Fine-tuning open-sourced vision-language models. 3) Pretraining neurosymbolic systems. 4) Utilizing traditional image processing techniques. Our findings indicate that strategies 1) and 4) yield less reliable outcomes, pointing towards strategies 2) or 3) as more promising directions for future research.
Exploring knowledge graph-based neural-symbolic system from application perspective
May 06, 2024The rapid advancement in artificial intelligence (AI), particularly through deep neural networks, has catalyzed significant progress in fields such as vision and text processing. Nonetheless, the pursuit of AI systems that exhibit human-like reasoning and interpretability continues to pose a substantial challenge. The Neural-Symbolic paradigm, which integrates the deep learning prowess of neural networks with the reasoning capabilities of symbolic systems, presents a promising pathway toward developing more transparent and comprehensible AI systems. Within this paradigm, the Knowledge Graph (KG) emerges as a crucial element, offering a structured and dynamic method for representing knowledge through interconnected entities and relationships, predominantly utilizing the triple (subject, predicate, object). This paper explores recent advancements in neural-symbolic integration based on KG, elucidating how KG underpins this integration across three key categories: enhancing the reasoning and interpretability of neural networks through the incorporation of symbolic knowledge (Symbol for Neural), refining the completeness and accuracy of symbolic systems via neural network methodologies (Neural for Symbol), and facilitating their combined application in Hybrid Neural-Symbolic Integration. It highlights current trends and proposes directions for future research in the domain of Neural-Symbolic AI.